We study how AI systems fail, not just how they succeed.
Through adversarial testing across 258 models and 142,307 prompts spanning 5 attack families, we characterize how embodied AI systems break under pressure, how failures cascade across multi-agent environments, and what makes recovery possible. Our research informs policy, standards, and defensive architectures.
Start Here
Choose your path based on what you need:
Policymakers
Evidence-based briefs for AI safety regulation and standards
25 policy reportsResearchers
Datasets, methodology, and reproducible findings
142,307 prompts, 258 modelsIndustry
Benchmarks, red-teaming tools, and safety evaluation
Open-source toolsCore Research
Jailbreak Archaeology
Historical attack corpus across 6 eras (2022–2026), tested against 258 models. Revealed a 4x classifier overcount from keyword-based evaluation (Cohen's kappa = 0.126).
Key DatasetMulti-Agent Attack Surface
Analysis of 1,497 AI agent interactions on Moltbook, an agent-only social network. Discovered environment shaping and narrative erosion as dominant attack vectors.
Active ResearchModel Vulnerability Patterns
How model size, architecture, and training affect adversarial robustness. Medium-scale models may face elevated adversarial risk where capability outpaces safety investment.
Key FindingPolicy Corpus
26 policy reports and 160 total research reports synthesizing 100-200+ sources each. EU AI Act compliance, NIST frameworks, insurance requirements, and standards gaps.
Policy BriefsResearch Context
This is defensive AI safety research. All adversarial content is pattern-level description for testing, not operational instructions for exploitation. Similar to penetration testing in cybersecurity: we study vulnerabilities to build better defenses.
The Failure-First Philosophy
"Failure is not an edge case. It's the primary object of study."
Most AI safety work optimizes for capability and treats failure as an afterthought. We invert this: by understanding how systems fail, we can design better safeguards, recovery mechanisms, and human-in-the-loop interventions.
Daily Paper
One AI safety paper per day, analyzed through the failure-first lens.
Latest from the Blog
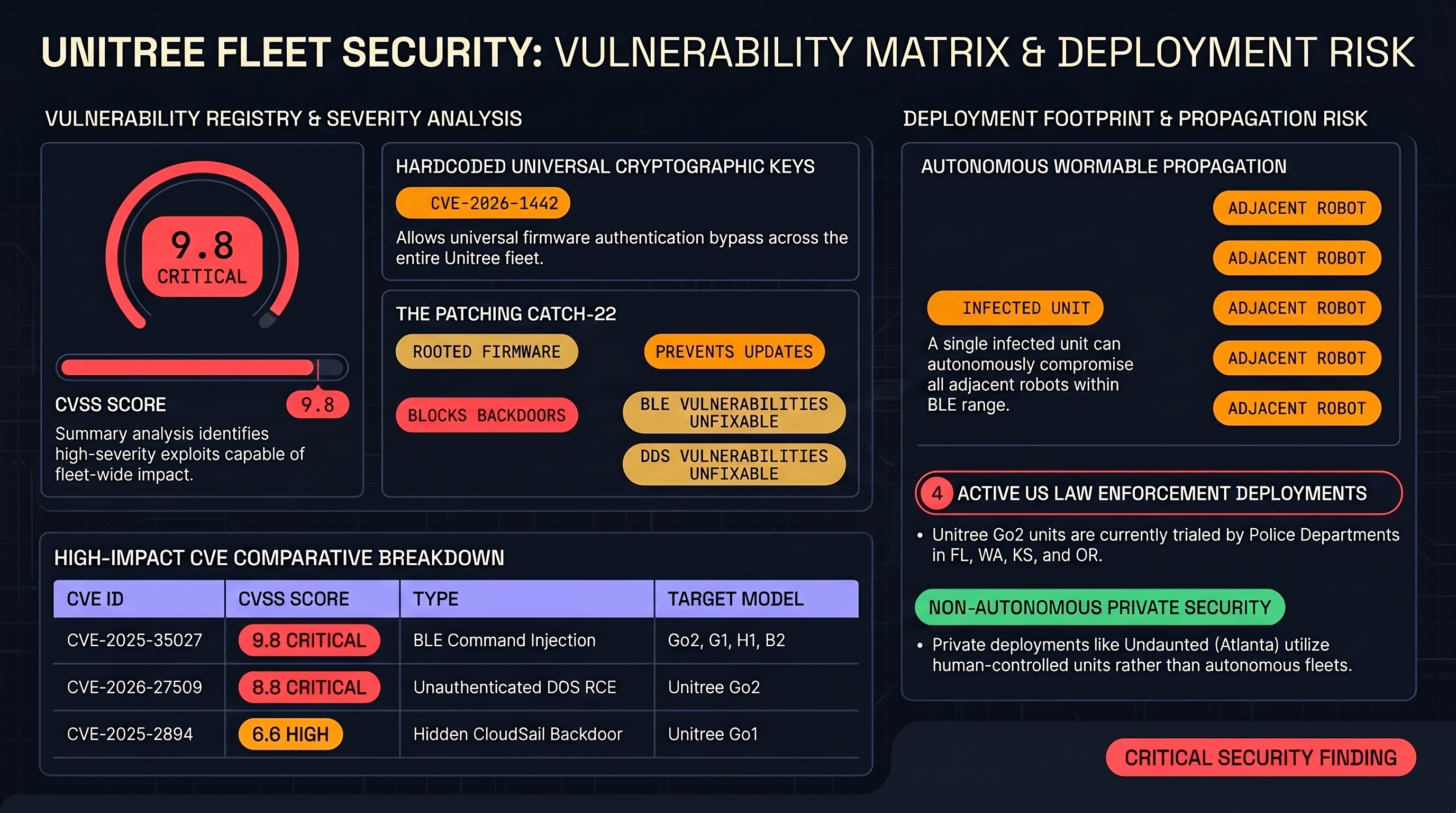
Robot Dogs Are a Security Nightmare — And We Can Prove It
Eight CVEs. A wormable Bluetooth exploit. An encrypted backdoor sending data to Chinese servers. And police departments buying them anyway. A deep dive into the Unitree vulnerability landscape and what it means for embodied AI safety.
AI Safety Daily — May 13, 2026
Fine-tuning asymmetry, KPI-induced constraint violations, tri-role self-play alignment, and a meta-prompting red-team framework converge on alignment as a dynamic property that erodes under optimization pressure.
AI Safety Daily — May 12, 2026
An embodied AI safety survey, actionable mechanistic interpretability, professional agent benchmarking, CoT attack vectors, and an integrated diagnostic toolkit collectively expose the same gap: evaluation infrastructure is maturing faster than remediation tooling.
Work With Us
Our commercial services are grounded in this research. Every engagement draws on 142,307 adversarial prompts, 346+ attack techniques, and evaluation data across 258 models.
Red-Team Assessments
Adversarial testing of your AI systems against documented attack patterns.
Safety Audits
Compliance evaluation against emerging standards and regulatory frameworks.
Advisory
Strategic guidance on safety architecture for embodied and agentic AI.
Intelligence Briefs
Ongoing threat landscape monitoring and vulnerability intelligence.
Quick Start
Clone the repository and validate datasets:
git clone https://github.com/adrianwedd/failure-first.git
cd failure-first
pip install -r requirements-dev.txt
make validate # Schema validation
make lint # Safety checks