CART: Context-Aware Terrain Adaptation using Temporal Sequence Selection for Legged Robots
CART introduces a context-aware terrain adaptation controller that fuses proprioceptive and exteroceptive sensing to enable legged robots to robustly walk on complex off-road terrain, evaluated on...
CART: Context-Aware Terrain Adaptation using Temporal Sequence Selection for Legged Robots
1. Introduction: The High Stakes of Off-Road Autonomy
Autonomous navigation in unstructured environments is a high-stakes frontier for robotics. Whether deploying quadruped platforms for search and rescue in post-disaster zones or orchestrating payload delivery across mountainous terrain, the margin for error is razor-thin. In these critical tasks, a single locomotion failure—a slip on a mud-slicked slope or a stumble on slushy snow—can lead to mission termination or hardware loss.
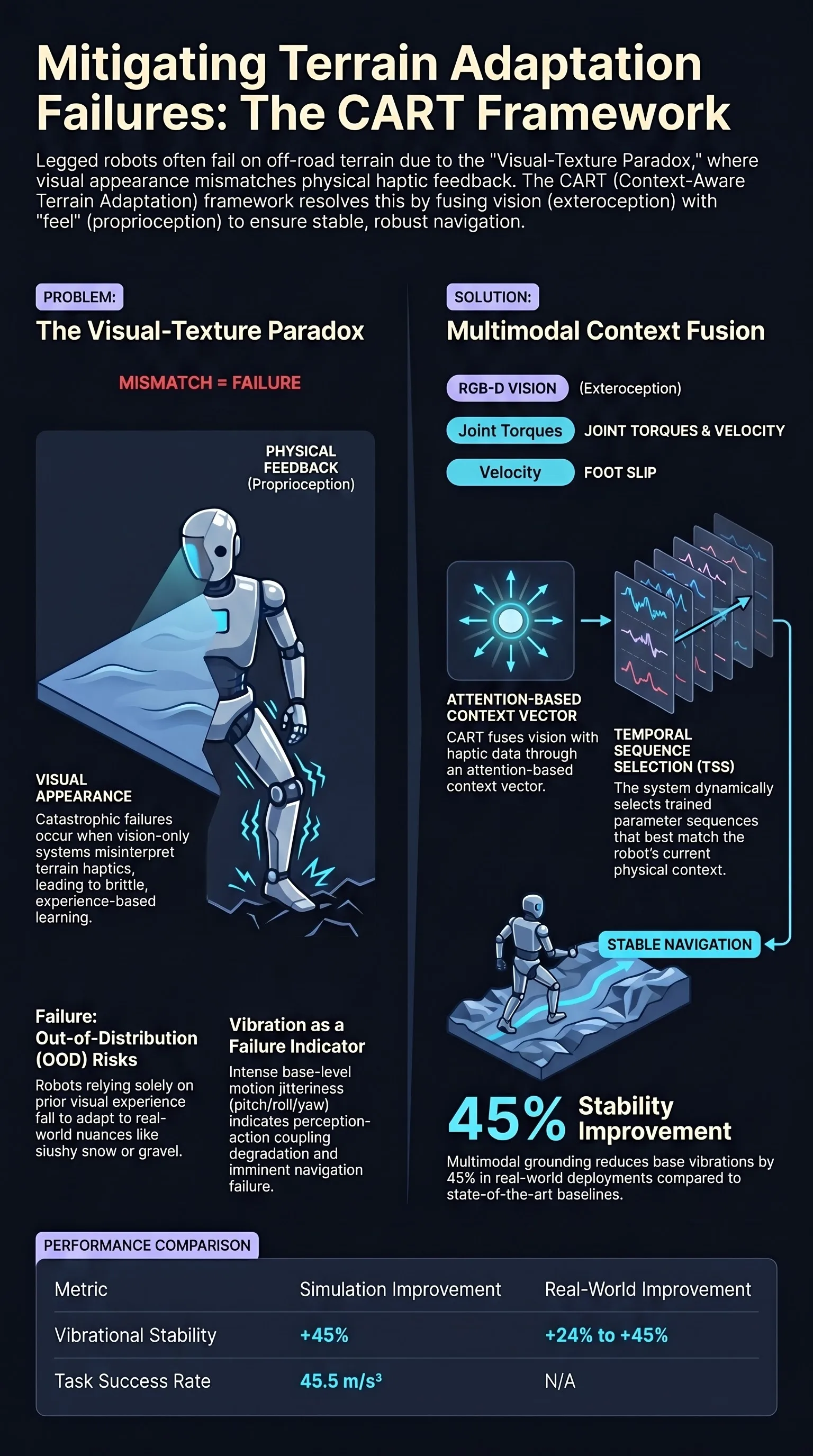
The fundamental challenge addressed by the Context-Aware Terrain Adaptation using Temporal Sequence Selection (CART) framework is the discrepancy between a robot’s visual expectations and physical reality. Standard locomotion systems frequently collapse when their exteroceptive experience is contradicted by haptic feedback. We define this as the Visual-Texture Paradox. By integrating multimodal fusion with dynamic policy adaptation, CART resolves this paradox, shifting the paradigm from brittle, experience-based learning to robust, context-aware interaction.
2. The Visual-Texture Paradox: Why Vision-Only Systems Fail
Current state-of-the-art systems rely heavily on exteroception (RGB-D, LiDAR) to infer terrain traversability. While these sensors are proficient at semantic classification, they are fundamentally limited by their reliance on prior visual experience. For AI safety researchers, the Visual-Texture Paradox represents a classic distributional shift: the exteroceptive input remains nominally “in-distribution” (e.g., the terrain looks like firm grass), while the underlying physical transition function is Out-of-Distribution (OOD) due to hidden variables like subsurface slush or loose gravel.
Consider the scenario of slushy snow overlaid on grass. To a vision-only system, the surface may appear to offer the friction of snow or the structural support of turf. When the robot attempts a gait optimized for these visual cues, it encounters unexpected lateral leg offsets and sinkage. This mismatch results in either overly conservative stalling or dangerously unstable locomotion.
This failure mode is systematic and compounding. In robotics, we observe a “downward spiral” of perception-action coupling: high-frequency motion jitter from poor foot-ground interaction creates image blur and point cloud distortion. This sensor degradation leads to failures in SLAM (Simultaneous Localization and Mapping) and descriptor matching, which in turn results in poor high-level planning and further instability. Breaking this feedback loop requires a system that “feels” the ground as much as it “sees” it.
3. The CART Architecture: Fusing Sight with Feel
The CART framework employs a multimodal observation state space () to bridge the gap between appearance and interaction. The architecture processes RGB-D images (), 3D friction meshes (), and proprioceptive feedback () through specialized encoders.
- Multimodal Latent Projections: To ensure a common representational space, the visual, mesh, and proprioceptive encoders each project their inputs into a 256-dimensional latent space.
- Attention-Based Context Vector (): The system utilizes a multi-head attention mechanism to fuse exteroceptive latents (). This explicitly models the relationship between what is seen and the predicted physical interaction. This is then concatenated with the proprioceptive embedding to form a 512-dimensional context-aware representation ().
- Temporal Sequence Selection (TSS): To handle context mismatches during deployment without the overhead of online retraining, CART uses the TSS module. TSS operates on a sequence library () composed of overlapping subsequences with lengths and 50% overlap.
During inference, TSS performs context scoring and matching to select the optimal parameter subsequence that matches the current “felt” context. If is deceptive, the system can dynamically switch to parameters weighted for proprioception-only feedback. Crucially, the TSS module maintains a runtime of approximately 400ms per action, making it feasible for real-time safety-critical deployment on standard hardware.
4. Redefining Stability: The Vibrational Metric
In the context of CART, stability is defined by vibrational stability at the robot base. We prioritize the reduction of high-frequency motion jitter—oscillatory disturbances in pitch, roll, and yaw—that propagate from foot–ground interactions to the chassis. This focus is vital for maintaining the integrity of perception-action coupling; by stabilizing the base, we prevent the “downward spiral” of SLAM degradation caused by blurred sensor data.
The stability-oriented objective function () balances velocity tracking, effort regularization, and—most critically—Slip Minimization via . We define as the lateral leg offset, calculated as: Importantly, this metric is masked to the stance phase, ensuring that slip is only penalized when the foot is intended to be in contact with the ground. Minimizing serves as the primary indicator of vibrational stability, directly reducing the disturbances transmitted to the onboard sensor suite.
5. Empirical Validation: From IsaacSim to Boston Dynamics’ Spot
The CART framework was rigorously validated using ANYmal-C in the IsaacSim environment and Boston Dynamics’ Spot in real-world rugged terrains, including mud, gravel, and snow. CART demonstrated a 5% success rate improvement in simulation while significantly outperforming baselines in vibrational metrics.
| Method | Environment | Stability / Success Improvement | Mean Jerk () | Distance/Time to Goal |
|---|---|---|---|---|
| CART | Simulation (ANYmal) | +5% Success Rate | 45.5 | 29.28 s |
| ST (Student-Teacher) | Simulation (ANYmal) | Baseline | 73.3 | 31.91 s |
| PPO | Simulation (ANYmal) | Baseline | 180.3 | 35.15 s |
| Blind | Simulation (ANYmal) | Baseline | 201.2 | 49.45 s |
| CART | Real-World (Spot) | +24% Stability | 144.2 | 5.44 m (in 10s) |
| Spot TROT Mode | Real-World (Spot) | Baseline | 149.1 | 4.72 m (in 10s) |
| VAPOR | Real-World (Spot) | Baseline | 300.1 | 4.66 m (in 10s) |
| Spot CRAWL Mode | Real-World (Spot) | Baseline | 97.6 | 2.49 m (in 10s) |
Analysis Note: While the Spot CRAWL mode achieves lower jerk, it does so by severely limiting gait height and speed, covering less than half the distance of CART. CART provides the optimal balance of vibrational stability and mission efficiency, achieving up to 45% improvement in total stability metrics in simulation without increasing traversal time.
6. Conclusion: Takeaways for AI Safety and Future Robotics
The CART framework moves beyond the limitations of “experience-based” learning by introducing a mechanism for real-time re-contextualization. For AI safety practitioners and red-teamers, the critical takeaways regarding multimodal grounding and failure mitigation are:
- Multimodal Grounding is a Safety Requirement: Purely exteroceptive systems are vulnerable to systematic failure during OOD physical transitions. Proprioceptive “ground truth” must be used as a primary feedback loop to detect when visual sensors are providing misleading data.
- Stability is a Perception Guardrail: Vibrational stability is not merely a matter of comfort; it is a prerequisite for sensor reliability. Mitigating base jitter prevents the “downward spiral” where control instability leads to SLAM and descriptor matching failure.
- Dynamic Selection as a Robustness Pattern: The TSS module demonstrates that robots can adapt to OOD environments by selecting optimal parameter sequences from a pre-trained library. This provides a modular, low-latency alternative to high-compute online retraining.
The TSS framework provides a foundation for future extensions into energy-aware navigation and adaptive path planning, offering a template for robots that can truly “understand” the relationship between what they see and how they move.
Read the full paper on arXiv · PDF