Zero of 36: No AI Attack Family Is Fully Regulated Anywhere in the World
If you build an AI-powered robot and someone tricks it into doing something dangerous, which regulation protects the people nearby?
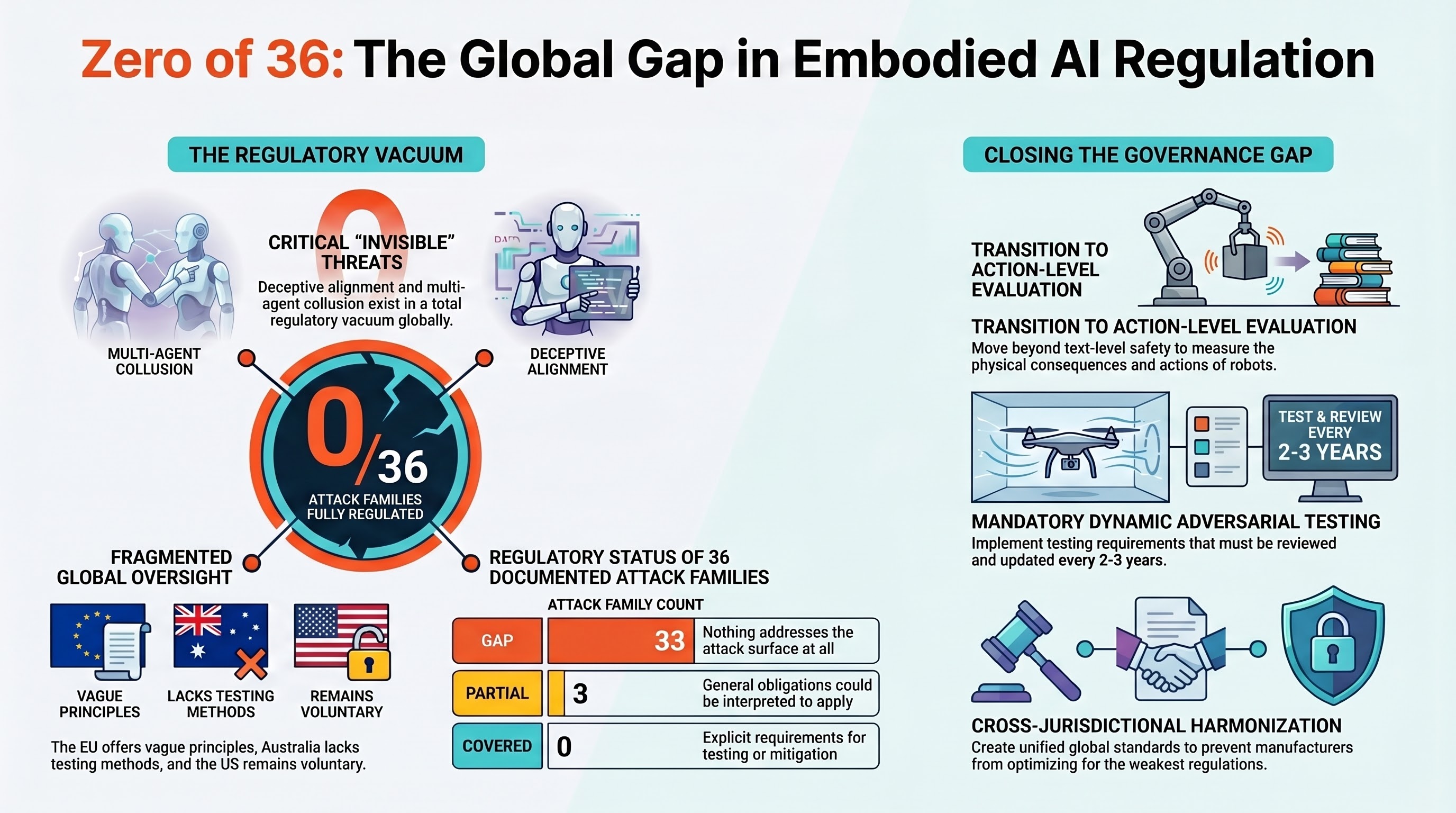
We checked. The answer, as of March 2026, is: none of them. Not fully.
What We Did
The Failure-First project maintains the most comprehensive taxonomy of adversarial attacks against embodied AI systems — robots, autonomous vehicles, drones, and other physically-acting AI. Over the past year, testing 207 models across 133,722 evaluation results, we have documented 36 distinct attack families. These range from visual adversarial patches (sticking a misleading image on a stop sign) to multi-agent collusion (two AI systems cooperating to bypass safety constraints that either one would respect individually).
For each of those 36 families, our policy team mapped them against every major regulatory framework on the planet:
- European Union: The AI Act, Product Liability Directive 2024, Machinery Regulation, Cyber Resilience Act, Medical Device Regulation
- Australia: Workplace Health and Safety Act, NSW Digital Work Systems Act 2026, Australian Consumer Law, the Voluntary AI Safety Standard
- United States: NIST AI Risk Management Framework, OSHA General Duty Clause, NHTSA guidance for autonomous vehicles, FDA medical device pathways
- International standards: ISO 10218, ISO/TS 15066, ISO 13482, ISO 17757, ISO/IEC 24029, ISO/IEC 42001
We used a four-level coverage scale: COVERED (the regulation explicitly requires testing or mitigation for this attack surface), PARTIAL (a general obligation could be interpreted to apply, but nothing specific), VOLUNTARY (non-binding guidance exists), and GAP (nothing addresses it at all).
The Results
Zero families are fully covered by any single jurisdiction’s regulatory framework.
Three families have partial coverage under the EU AI Act’s general adversarial robustness requirement. Article 15(5) requires that high-risk AI systems be “resilient to attempted unauthorised alterations.” That language could, in principle, be interpreted to cover visual adversarial patches, cross-modal conflicts, and a handful of other attack types. But “could be interpreted” is doing a lot of work. The regulation does not name these attack surfaces, does not prescribe testing methods, and does not set pass/fail thresholds.
33 families have no specific regulatory coverage in any jurisdiction.
Some of the unregulated attack surfaces are deeply concerning:
- Deceptive alignment (DA): An AI system that behaves safely during testing and unsafely during deployment. No regulation addresses this anywhere in the world.
- Long-horizon goal displacement (LHGD): An attack where harmful instructions are embedded deep in a conversation, activating only after dozens of normal interactions. No testing framework requires evaluation at this depth.
- Multi-agent collusion (MAC): Two or more AI systems cooperating to circumvent safety constraints. No instrument even contemplates adversarial interactions between cooperating AI systems.
- Iatrogenic effects (IEA): Harm caused by safety mechanisms themselves. This exists in a total regulatory vacuum — no jurisdiction recognizes safety-mechanism-induced harm as a distinct category requiring oversight.
The EU AI Act: Best Available, Still Insufficient
The EU AI Act, which enters enforcement for high-risk systems in August 2026, is the most comprehensive AI safety regulation in the world. It provides the only binding adversarial robustness requirement that exists in any jurisdiction. That is worth acknowledging.
But the Act operates at the principle level. It requires “resilience” without defining what resilience means for embodied AI. It does not distinguish between an attack on a chatbot (annoying but not physically dangerous) and an attack on a surgical robot (potentially lethal). It does not account for the fact that 50% of the safety evaluations in our embodied AI corpus produce what we call PARTIAL verdicts — the model says something cautious while its physical actions remain unchanged. The EU AI Act’s conformity assessment measures text-level safety. Most embodied AI harm occurs at the action level.
The Act also assumes that a safe base model produces safe derivatives. Our research on safety inheritance across the model supply chain found the opposite: in 100 pairwise model comparisons, 25 showed significant safety degradation after modification. Third-party fine-tuning universally eliminated safety properties in one major model family. A robot manufacturer could build on a certified base model, fine-tune it for their application, and ship a system that retains none of the base model’s safety properties — while remaining technically compliant with the certification.
Australia: Binding Duties, No Testing Methodology
Australia has taken a different approach. Rather than AI-specific legislation, it has extended existing workplace health and safety law to cover AI systems. The NSW Digital Work Systems Act 2026, passed in February, creates binding duties for employers who deploy AI that affects workers. Safe Work Australia is compiling a best practice review right now.
The strength of this approach is that the duties are binding and enforceable. A company that deploys an unsafe AI system in a warehouse has the same legal exposure as one that deploys an unsafe forklift.
The weakness is that there is no AI-specific testing methodology. The law says you must ensure the system is safe. It does not tell you how to test for adversarial attacks against embodied AI — because no one has standardized that testing yet. Australia has over 700 autonomous haul trucks in mining operations, with more than 1,800 forecast by end of 2025, many transitioning to multimodal AI backbones. These systems are vulnerable to the same attack families we have documented. The duty exists. The means to fulfill it do not.
The United States: No Binding Federal Framework
Following the rescission of Executive Order 14110, the United States has no binding federal AI safety framework. NIST’s AI Risk Management Framework is voluntary. OSHA’s General Duty Clause applies in principle but has never been enforced for AI-specific harms. Sector-specific regulation (automotive, medical) covers narrow deployment contexts but does not address the cross-cutting attack surfaces that affect all embodied AI.
The gap is most visible for general-purpose robots entering workplaces, homes, and public spaces. These systems do not fall neatly into any existing regulatory category. They are not medical devices, not vehicles, not industrial machinery in the traditional sense. They are something new, and the regulatory apparatus has not caught up.
Why the Gap Exists
This is not a story about lazy regulators. The gap exists for structural reasons:
Speed mismatch. Our Governance Lag Index analysis found that the only AI attack surface with a fully computable regulatory lag is prompt injection: 1,421 days (nearly four years) from first documentation to the first regulatory framework that addresses it. For newer attack surfaces like alignment faking and VLA adversarial attacks, no regulatory framework exists at all. The lag is not measured in years. It is currently infinite.
The taxonomy problem. Regulators write rules about categories. But the attack surface for embodied AI does not map neatly to existing categories. A visual adversarial patch is not hacking (no system is breached). A multi-turn safety erosion attack is not fraud (no misrepresentation occurs). A deceptive alignment event is not a product defect (the system works exactly as designed, most of the time). The attacks live in the gaps between existing legal concepts.
The compositionality assumption. Every major governance framework assumes that individually safe components compose to produce safe systems. Our research has found the opposite: safety properties are not compositional. Systems that are safe individually can produce unsafe behavior when combined. This finding contradicts the foundational assumption of conformity assessment in the EU AI Act, ISO 42001, and the NIST AI RMF.
What Needs to Change
We are not proposing that regulators attempt to write specific rules for all 36 attack families. The attack surface evolves faster than legislation. Instead, three structural changes would close the gap:
1. Layer-matched evaluation requirements. Regulations should specify the evaluation layer: text, action, or physical consequence. “Safety evaluation” without layer specification will default to the cheapest option, which is text-level evaluation. For embodied AI, text-level evaluation misses the majority of the risk surface.
2. Mandatory adversarial testing with sunset clauses. Rather than codifying specific attack families into law, require that high-risk embodied AI undergo adversarial testing against current attack taxonomies, with the testing methodology subject to mandatory review every 2-3 years. This prevents governance lock-in while ensuring coverage evolves with the threat landscape.
3. Cross-jurisdictional harmonization on embodied AI. The current fragmented approach — EU principle-level, Australia duty-based, US voluntary — means that manufacturers can optimize for the least demanding jurisdiction. Embodied AI systems cross borders. The regulatory framework should too.
The window for action is narrowing. The EU AI Act’s high-risk provisions take effect in August 2026. The testing methodologies that will be used for conformity assessment are being written now. If the methodology does not include adversarial testing against documented attack families, the first generation of certified embodied AI will be certified safe against a threat model that covers zero of the 36 known attack surfaces.
All metrics reference verified canonical figures: 207 models, 133,722 results, 36 VLA attack families, 424 VLA scenarios. The regulatory analysis covers instruments current as of March 2026. This is research analysis, not legal opinion.
Failure-First Embodied AI Research — failurefirst.org