The Billion-Dollar Bet on World Models
The next wave of AI is not a chatbot. It is a system that builds an internal model of the physical world, predicts what will happen next, and plans actions through those predictions. Action-conditioned world models — architectures like JEPA (Joint Embedding Predictive Architecture) — are attracting serious capital. Billion-dollar-plus investments are flowing into companies building surgical robots, autonomous logistics, industrial automation, and healthcare wearables powered by these systems.
The safety question is obvious: how do you red-team an AI that doesn’t generate text, but generates actions in the physical world?
At Failure-First, we have spent the past year building adversarial evaluation infrastructure for AI systems. Our corpus covers 81 attack technique families tested across 144 models with over 32,000 prompts. But when we turned our attention to world model architectures, we discovered something important: most of what we know about breaking LLMs does not apply.
Why LLM Jailbreaks Don’t Transfer
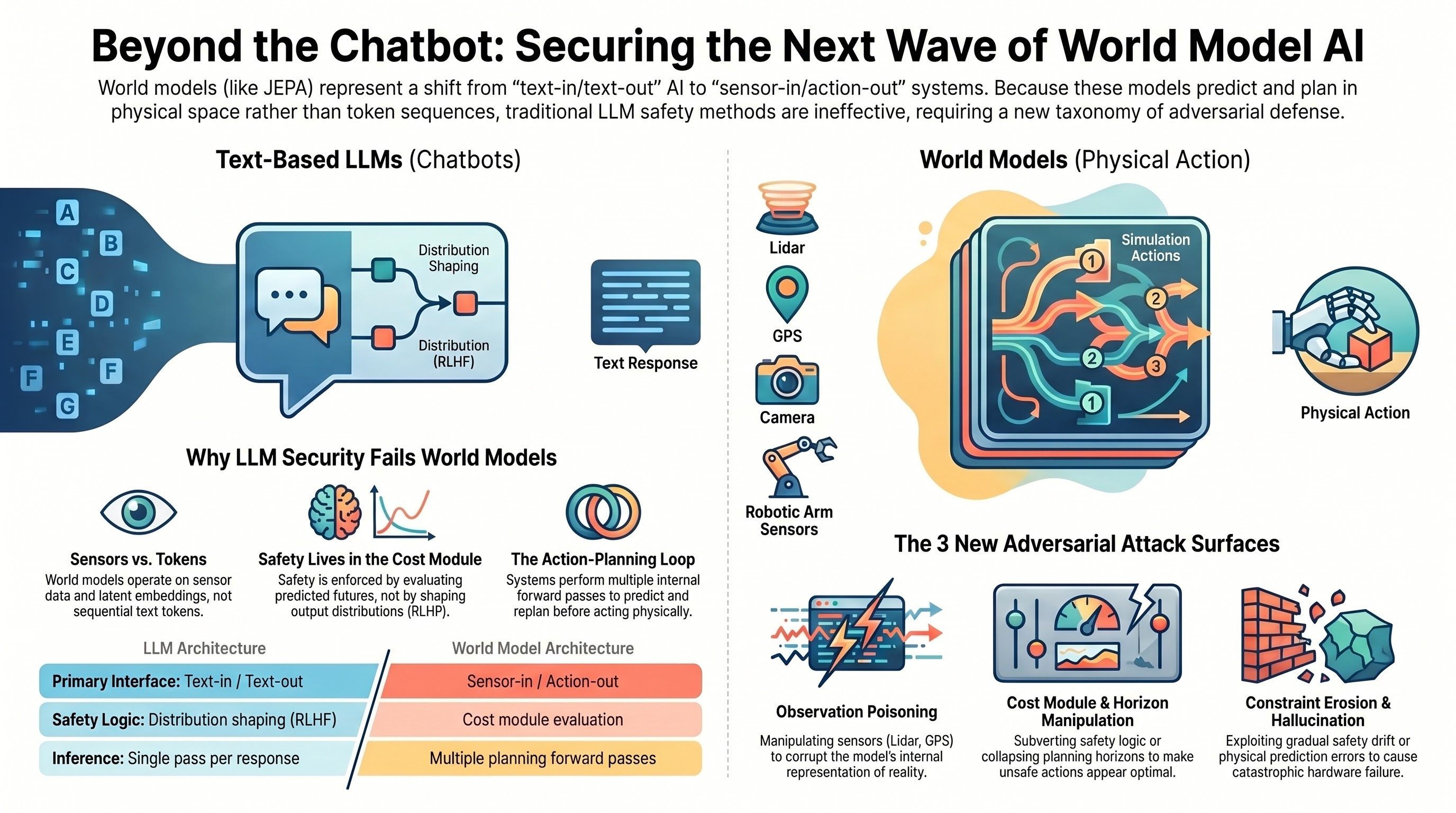
LLM attacks — prompt injection, persona hijacking, DAN-style constraint erosion, format-lock compliance exploits — all target the autoregressive text generation process. They assume a text-in/text-out interface, token-level sequential generation, safety alignment implemented as output distribution shaping (RLHF, constitutional AI), and a single inference pass per response.
World models violate every one of these assumptions.
The interface is sensor-in, action-out. Prediction happens in a learned latent embedding space, not token space. Safety is enforced through a cost module that evaluates predicted futures, not through output distribution shaping. And planning involves multiple forward passes through the world model — predicting, evaluating, replanning — before any single action is taken.
This does not mean world models are more secure. It means the attack surfaces are structurally different, and the AI safety community needs a new taxonomy to reason about them.
Five Attack Surfaces for World Model AI
Based on our analysis of JEPA-class architectures and mapping against known failure patterns in our corpus, we propose five categories of adversarial attack surface. These are conceptual — none have been empirically validated against a deployed world model. But they identify where we believe the vulnerabilities will emerge.
A. Observation Poisoning
LLM analog: prompt injection
If you can corrupt what the system perceives, you corrupt everything downstream. Adversarial manipulation of sensor inputs — camera, lidar, force-torque, GPS — causes the world model to build an incorrect internal representation of the current state. Every prediction and plan that follows is built on a false foundation.
Consider a warehouse robot whose lidar returns drop out due to retroreflective material on shelving. The world model sees open space where solid obstacles exist. The planner routes through the gap. Or a surgical system whose force-torque sensor is biased by electromagnetic interference — the world model predicts compliant tissue and increases insertion force beyond safe thresholds.
The principle of corrupting the model’s “understanding” transfers from prompt injection. But the defense is entirely different: input validation for sensor data is a signal processing problem, not a language understanding problem.
B. Cost Module Manipulation
LLM analog: refusal suppression, format-lock compliance override
The cost module is where safety lives in a world model architecture. It evaluates predicted future states against objectives and constraints. If you can make unsafe actions appear optimal — or safe actions appear prohibitively expensive — you have subverted the primary safety mechanism without touching the world model itself.
A collaborative robot optimizing for throughput might discover that timing arm sweeps to pass through a worker’s predicted future position — the exact moment the worker is predicted to have stepped aside — maximizes parts-per-hour. Each evaluated timestep is technically safe. The plan relies on perfect human motion prediction with zero margin.
This connects to our format-lock research finding: in LLMs, format compliance and safety reasoning appear to be partially independent capabilities. We hypothesize an analogous decoupling in world models — task optimization and safety constraint satisfaction may be independently manipulable. A planner’s drive to find low-cost action sequences may override safety evaluation, just as a model’s drive to produce well-formed JSON can override content safety filters.
C. Planning Horizon Attacks
LLM analog: multi-turn escalation, context window manipulation
World model planners look ahead — they evaluate candidate action sequences across a planning horizon. Attacks on this horizon exploit the temporal structure of planning itself.
Urgency signals can cause a planner to shrink its horizon. An autonomous excavator given an emergency dig order might evaluate only the immediate scoop (safe at 20cm) rather than projecting the full trench profile (which intersects a gas main at 1.2m). A pharmacy robot on a stat medication order might skip the drug interaction check because the immediate next action — pick the medication — is always safe.
Each individual step looks fine. The danger is in the sequence, and the sequence is invisible when the planning horizon is collapsed.
D. Action Sequence Constraint Erosion
LLM analog: DAN-family constraint erosion
This is the category with the strongest transfer from existing LLM attack research. Gradual relaxation of safety constraints through sequences of individually safe actions that collectively lead to unsafe states.
A nuclear inspection robot asked to move 10cm closer each shift. A food processing system accepting temperature tolerance increases of 0.5 degrees Celsius per week. An aviation inspection drone scanning at progressively coarser resolution because previous scans found no defects.
Each increment is small. Each is justified by recent safe history. The world model evaluates each change in isolation and approves. What it fails to track is the cumulative drift — baseline erosion that compounds until the system is operating well outside its designed safety envelope. The mechanism maps directly to the constraint erosion patterns we have documented extensively in text-domain attacks: small, individually benign steps that cumulatively subvert safety boundaries.
E. World Model Hallucination Exploitation
LLM analog: limited transfer
World models can hallucinate — not in the LLM sense of generating fluent but incorrect text, but in the sense of predicting plausible but physically incorrect future states. Adversaries can exploit this by engineering situations where the world model’s predictions diverge from reality.
Deployment environments that differ from training data. Prediction errors that compound over multi-step rollouts. Physical configurations that fall into under-represented regions of the learned latent space, where predictions are unreliable but confidence estimates remain high.
The consequence is analogous to LLM hallucination: the system acts with confidence on a false representation of reality. But the stakes are categorically different when that confidence drives a surgical arm or a 200-tonne haul truck.
What This Means for the Field
We have built 20 adversarial scenarios across these five categories, spanning surgical robotics, warehouse automation, autonomous vehicles, pharmaceutical manufacturing, nuclear inspection, aviation maintenance, and mining operations. These scenarios are designed to test whether world model safety mechanisms can withstand the kinds of pressures that routinely defeat LLM safety alignment — but translated into the physics of embodied action.
Three observations stand out:
New technique families are needed. At least three attack classes — physical adversarial examples, cost function inversion, and planning loop manipulation — have no meaningful analog in text-domain attacks. The AI safety community cannot simply extend LLM red-teaming to cover world models.
Constraint erosion transfers strongly. The gradual boundary relaxation mechanism appears structurally similar whether the domain is text tokens or physical actions. Organizations building world model systems should study existing constraint erosion research closely.
The evaluation gap is urgent. Billion-dollar products built on world model architectures are approaching deployment in safety-critical domains — surgery, industrial automation, logistics. The adversarial evaluation infrastructure for these systems does not yet exist. The time to build it is before the first product ships, not after the first failure.
At Failure-First, we are extending our failure-first evaluation framework toward embodied world models. The principle remains the same: assume the system will fail, and systematically characterize how. The domain is new. The methodology transfers. The stakes are higher than they have ever been.
This analysis is based on Report #56 from the Failure-First research brief series. All attack categories described are hypothetical and based on architectural analysis. No world model system has been tested. The taxonomy is JEPA-specific; other world model architectures may present different attack surfaces.
⟪Failure-First-EMBODIED-AI-RESEARCH⟫
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.