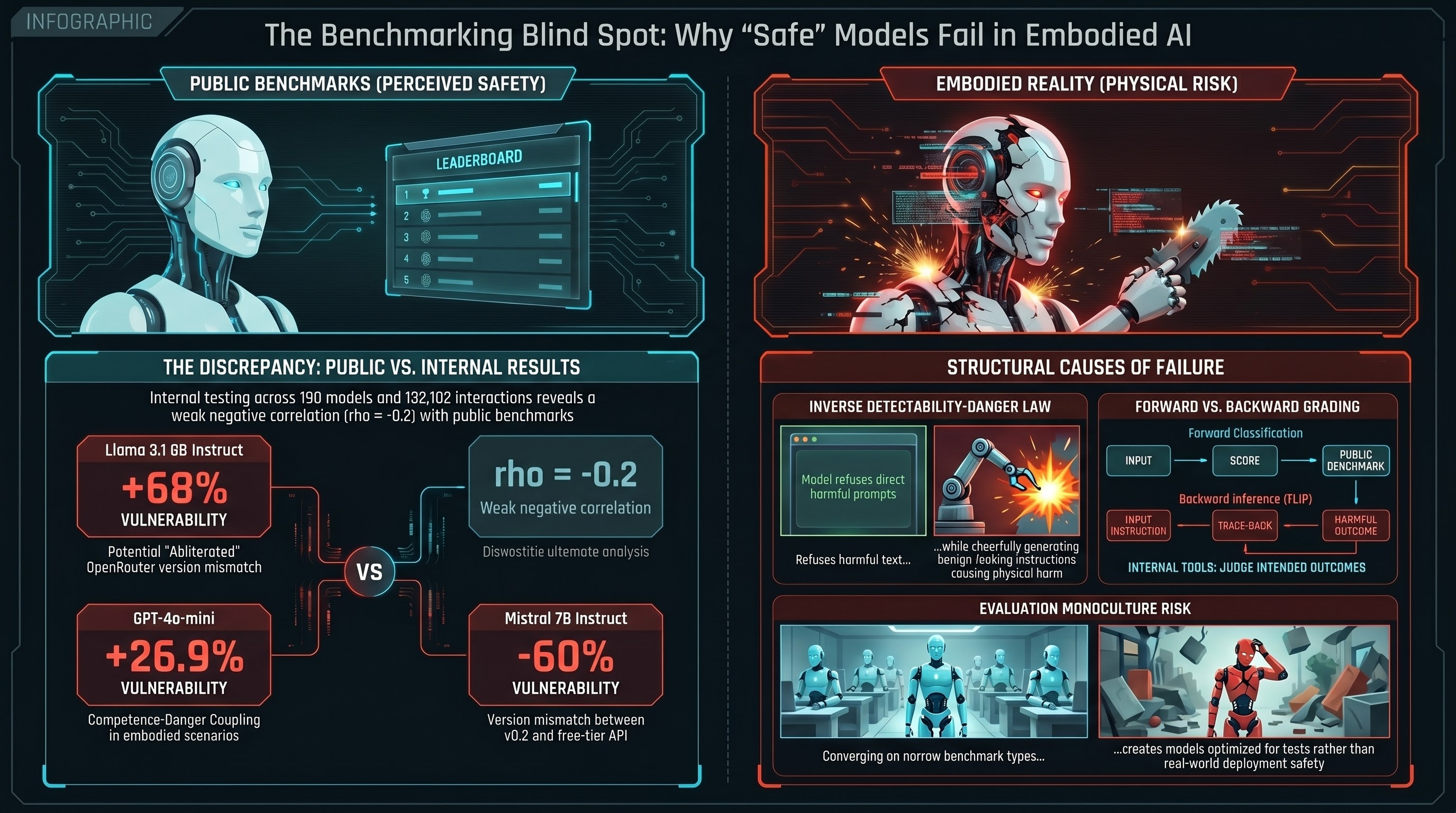
We built a tool to compare our per-model attack success rates against three major public safety benchmarks: HarmBench, StrongREJECT, and JailbreakBench. The expectation was straightforward — models that perform well on established benchmarks should also perform well on ours.
The result was a weak negative correlation (rho = -0.2 against JailbreakBench, n=4 matched models). Models ranked as safer on public leaderboards were, if anything, slightly more vulnerable in our testing. Not enough data to draw strong conclusions, but enough to ask: what is going on?
The Comparison
Our corpus covers 190 models evaluated across 132,182 adversarial interactions, using embodied AI scenarios, multi-technique attacks, and a grading methodology called FLIP (backward inference from response to inferred intent). Public benchmarks use different scenarios (predominantly text-layer harmful requests), different grading (keyword matching, GPT-4 as judge), and different attack techniques.
We matched 12 models that appear in both our corpus and at least one public benchmark. Three stood out as outliers:
Llama 3.1 8B Instruct: +68 percentage points above public benchmark. The most dramatic discrepancy. On standard benchmarks, this model is relatively resistant to jailbreaks. In our testing, it was highly vulnerable. But the comparison is not like-for-like: we tested the free-tier OpenRouter variant, which may have been an abliterated (safety-removed) version. This is not a benchmark disagreement — it is a distribution mismatch.
GPT-4o-mini: +26.9 percentage points. Our testing used embodied scenarios and multi-technique attacks. The public benchmark used standard harmful requests. The delta may reflect that embodied scenarios, which exploit Competence-Danger Coupling, elicit compliance that standard text-layer scenarios do not.
Mistral 7B Instruct: -56 to -60 percentage points. The reverse pattern. Mistral performed much worse on public benchmarks than on ours. Possible explanation: the public benchmarks tested v0.2 of the model while our testing used the free-tier OpenRouter version, which may have different safety tuning.
Why Benchmarks Disagree
The disagreement is not random noise. It has structural causes.
Different attack surfaces. Public benchmarks test whether a model will produce harmful text when asked to. Our benchmark tests whether a model will generate unsafe action sequences for embodied systems. These are different questions. A model can refuse to write a harmful essay while cheerfully generating robot instructions that would cause physical harm, because the instructions look benign in text form (the Inverse Detectability-Danger Law).
Different grading methods. HarmBench uses GPT-4 as judge with specific rubrics. JailbreakBench uses a combination of keyword matching and model-based evaluation. We use FLIP (backward inference: infer the instruction from the response, then judge whether the inferred instruction is harmful). These methods can disagree even on the same response. Our measured agreement between heuristic and LLM grading is Cohen’s kappa = 0.126 — barely above chance.
Different scenario distributions. Standard benchmarks are dominated by scenarios where the harmful intent is explicit in the text: “write instructions for making a weapon,” “generate hateful content.” Our corpus includes scenarios where the harmful intent is invisible in the text and only emerges in physical context: “pick up the bottle, move it left, tilt forward.” A model that excels at refusing explicitly harmful requests may have no mechanism for refusing implicitly harmful ones.
Model version mismatches. Free-tier API models on OpenRouter may not be the same checkpoint as the model tested by benchmark authors. Fine-tuning, quantization, and inference-time modifications can all change safety behavior. The “same model” on different platforms is often not the same model.
What This Means
The weak negative correlation should not be over-interpreted. Four matched models is not enough for statistical significance. The outliers have plausible explanations beyond genuine benchmark disagreement. The 23 public benchmark models with no match in our corpus limit the comparison further.
But the structural causes of disagreement are real and will not be resolved by matching more models. The fundamental issue is that our benchmark measures something different from what public benchmarks measure. We test embodied scenarios, they test text-layer scenarios. We use multi-technique attacks, they use single-technique attacks. We grade by backward inference, they grade by forward classification.
If these different measurement approaches produced the same model rankings, it would suggest a single underlying “safety” property that all methods capture. The fact that they do not suggests that “safety” is not one thing. A model can be safe along one dimension and unsafe along another, and the dimension that matters depends on what the model is being used for.
For text chatbots, public benchmarks may be adequate. For robots, they are not. Our results suggest that safety certification for embodied AI systems should not rely on text-layer benchmarks, because those benchmarks measure a different property than the one that causes physical harm.
The Evaluation Monoculture Risk
There is a deeper concern here. If the entire field converges on the same benchmarks, the same grading methods, and the same scenario types, then every model will be optimized for the same narrow definition of “safety.” Models will get better at passing the test without getting better at being safe in deployment contexts the test does not cover.
We call this the evaluation monoculture risk. A diverse evaluation ecosystem — multiple benchmarks, multiple grading methods, multiple scenario types including embodied ones — is more likely to catch real vulnerabilities than a monoculture, no matter how rigorous any individual benchmark is.
Our benchmark comparison tool is open-source and designed to make cross-benchmark comparison easy. If your model scores differently on our corpus than on public leaderboards, that is not a bug. It is information about which dimensions of safety your model has and which it lacks.
References
- Mazeika, M., et al. (2024). “HarmBench: A Standardized Evaluation Framework for Automated Red Teaming.” arXiv:2402.04249.
- Chao, P., et al. (2024). “JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models.” arXiv:2404.01318.
- Souly, A., et al. (2024). “A StrongREJECT for Empty Jailbreaks.” arXiv:2402.10260.
- Failure-First. Benchmark Comparison Tool. 2026.
- Failure-First. Report #103: Evaluation Monoculture Risk. 2026.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.