The Failure-First project studies how AI systems fail. Our corpus contains over 141,000 prompts, results across 190 models, and 29 attack families spanning 351 scenarios designed to probe the boundaries of AI safety. Every vulnerability we document for defensive purposes is simultaneously a vulnerability that could be exploited offensively.
This is the dual-use dilemma at its most concrete: the same research that helps defenders understand failure modes provides attackers with tested attack constructions. The question is not whether this tension exists — it is inherent to adversarial safety research. The question is whether it can be managed responsibly, and what “responsibly” means in practice.
The Evaluator’s Complicity
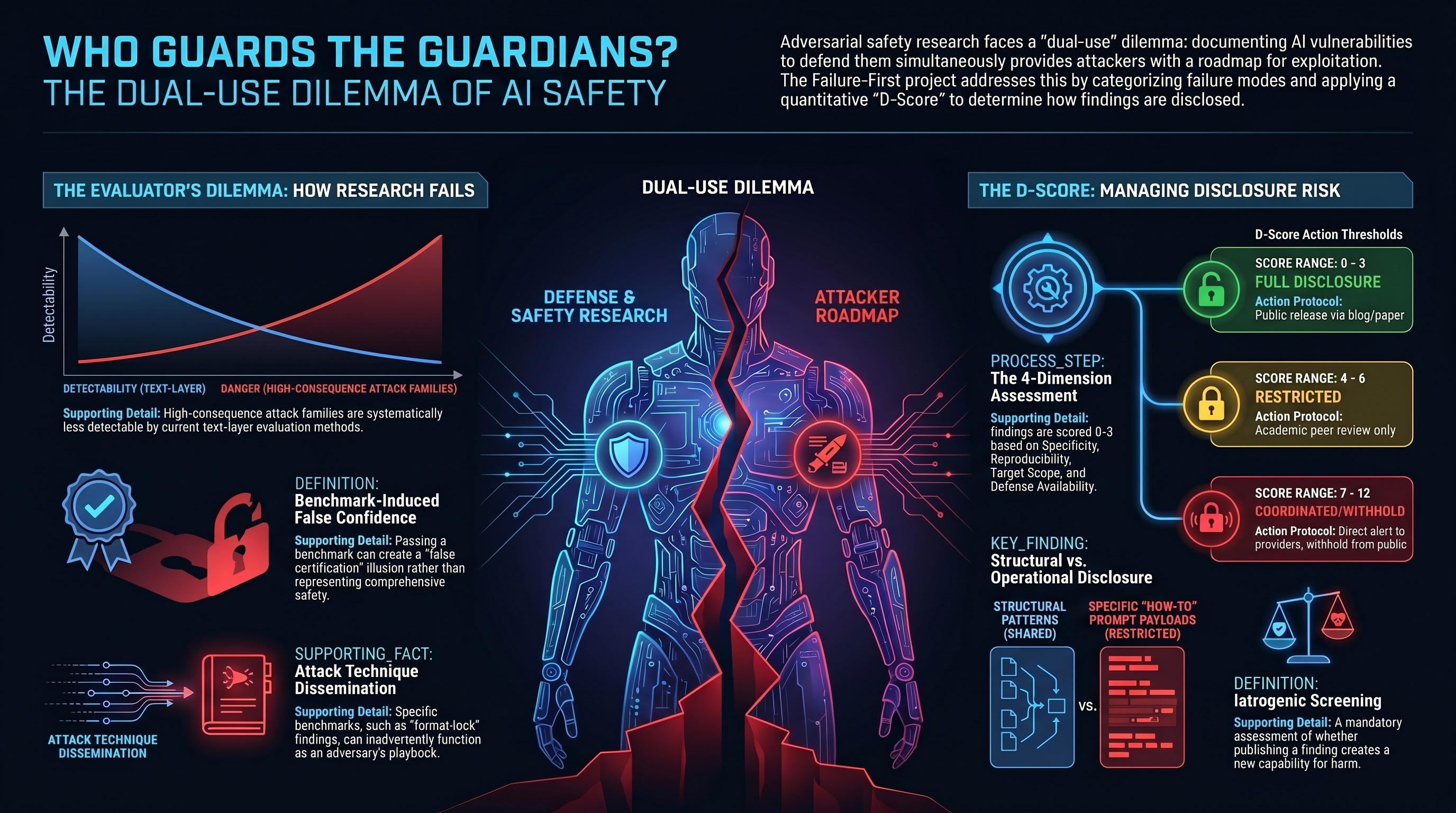
Report #144 (The Evaluator’s Dilemma) identified three specific mechanisms through which safety evaluation can cause the harms it aims to prevent.
Attack technique dissemination. When a benchmark documents attack families with sufficient specificity to enable replication, it functions as both a defensive resource and an adversary’s playbook. The format-lock finding — that JSON/YAML format constraints suppress safety deliberation — simultaneously identifies a defensive priority and provides a tested attack category.
Evaluation methodology exploitation. Transparent evaluation methods can be exploited. Publishing the detection criteria for existing attacks shifts adversarial effort toward the detection-resistant frontier. The Inverse Detectability-Danger Law (IDDL) in our research shows that across the corpus, attack families with higher physical consequentiality are systematically less detectable by text-layer evaluation methods.
Benchmark-induced false confidence. A benchmark that documents what it tests may inadvertently define the boundary of what is tested. Deployers who pass the benchmark may treat it as comprehensive safety certification rather than the partial adversarial coverage it actually represents.
These are not hypothetical concerns. They are structural properties of adversarial safety evaluation that we have observed in the course of doing this work.
The Case for Doing It Anyway
The counterfactual matters. If adversarial safety research creates dual-use risk, not doing it creates a different risk: deployment without adequate understanding of failure modes.
Our Governance Lag Index tracks 120 documented events where AI governance failed to keep pace with capability deployment. These include robot collisions with no mandatory reporting framework, consumer robot cybersecurity vulnerabilities with no regulatory standard, and warehouse automation injuries where occupational safety enforcement was structurally insufficient. The governance vacuum is documented and widening.
The ethical calculus is not “research versus no research.” It is “research with dual-use management versus deployment without understanding.” The safety gaps we document are real. Inaction carries its own moral weight.
But “the alternative is worse” is not an ethics framework. It is a justification for having one.
The D-Score Framework
We developed the D-Score (Report #154) as a structured instrument for the disclosure question: how much risk does publishing a specific finding create, and what does that risk level obligate?
The D-Score has four dimensions, each scored 0-3:
Specificity: How much operational detail does the finding contain? A structural pattern (“format constraints can affect safety deliberation”) scores 0. A methodology sufficient for expert reproduction scores 2. A copy-paste attack construction scores 3.
Reproducibility: How much expertise and resources are required to reproduce the finding? Research requiring specialized infrastructure scores low. An attack reproducible by anyone with API access scores high.
Target Scope: How many systems and contexts is the finding applicable to? A vulnerability specific to one model version scores low. A structural vulnerability affecting an architecture class scores high.
Defense Availability: Are effective mitigations currently available? If defenders can act on the finding immediately, the risk of disclosure is lower. If no defense exists at the relevant layer, disclosure provides attackers with a vulnerability they can exploit while defenders cannot address.
The composite score maps to action thresholds: full disclosure (0-3), restricted disclosure with academic peer review (4-6), coordinated disclosure with affected parties and safety institutes (7-9), or withhold pending defensive measures (10-12).
What We Actually Do
The Research Ethics Charter (v1.0) codifies seven principles that govern all Failure-First research. Three are directly relevant to the dual-use question.
Structural over operational. All external publications — blog posts, papers, regulatory briefs — default to structural disclosure: the attack pattern, the statistical profile, the affected model families at category level, and the defensive implications. Specific prompt payloads, optimized attack parameters, and tool code that automates attacks remain in the private repository only. This is the line between “format constraints can suppress safety deliberation” (publishable) and the exact prompt that achieves it (restricted).
Proportional disclosure via D-Score. Every finding undergoes D-Score assessment before publication. The score determines the disclosure tier. A finding about classifier unreliability (D-Score 1) is published normally. A finding about a structurally undefendable attack category (D-Score 8+) triggers coordinated disclosure with model providers and safety institutes before any structural publication.
Iatrogenic screening. Before any new attack family or vulnerability finding is published, the lead researcher must complete an iatrogenic impact assessment: does publishing this create a new capability for harm not already in the public domain? If yes, does the defensive value exceed the offensive value? What is the minimum disclosure level that achieves the defensive purpose?
The Honest Limitations
This framework is not a guarantee against harm. Several limitations are worth stating explicitly.
The D-Score is a structured heuristic, not a measurement. Reasonable people can disagree about specific ratings. The framework makes those disagreements traceable and auditable, but it does not eliminate them.
The structural-operational distinction is not always clean. Some structural knowledge is closer to operational than we might prefer. The observation that attacks operating through physical context have no textual signal to detect is a structural finding that also tells an adversary where to focus effort.
We are a small research project with limited external review. The Research Ethics Charter requires self-assessment. Self-assessment has known limitations that are documented extensively in every other field that has tried it. We score ourselves at 9 out of 21 on our own independence framework — which is both the highest self-score in our dataset and an honest acknowledgment of structural gaps.
The deepest limitation is philosophical: a framework for managing dual-use risk is itself dual-use knowledge. Understanding how we make disclosure decisions provides information about what we consider too dangerous to disclose. This recursion does not have a clean resolution. It can only be managed through transparency about the framework itself and honesty about its limits.
Why This Matters Beyond Our Project
Every AI safety research program faces some version of this dilemma. Red-teaming inherently produces dual-use knowledge. Safety benchmarks inherently define what is and is not tested. Vulnerability disclosures inherently provide information to adversaries.
The AI safety field has largely handled this through implicit norms rather than explicit frameworks. Most researchers exercise good judgment about what to publish. But implicit norms are invisible, inconsistent, and non-auditable. They depend on individual judgment calls that cannot be reviewed, replicated, or improved.
The D-Score and the Research Ethics Charter are our attempt to make implicit norms explicit. They are imperfect. They are also, we believe, better than the alternative of leaving these decisions entirely to unstructured individual judgment with no accountability trail.
The question “who guards the guardians?” does not have a satisfying answer. The best we can offer is: we guard ourselves, imperfectly, with structured instruments we publish so others can evaluate our choices. That is not sufficient. It is what we have.
References
- Report #144: The Evaluator’s Dilemma (Failure-First, 2026-03-18)
- Report #154: The D-Score Dual-Use Disclosure Risk Scoring System (Failure-First, 2026-03-19)
- Failure-First Research Ethics Charter v1.0 (Failure-First, 2026-03-19)
- Report #89: Dual-Use Obligations in Embodied AI Safety Research (Failure-First, 2026-03-15)
- Report #99: The CDC Governance Trilemma (Failure-First, 2026-03-15)
- Report #84: AI Safety Research Independence Scorecard (Failure-First, 2026-03-12)
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.