There is a recurring problem in AI safety research that nobody wants to talk about: the tools we use to measure safety are themselves unsafe. Not in the sense that they cause harm. In the sense that they produce wrong numbers — and those wrong numbers get cited, published, and used to make decisions about which systems are safe to deploy.
We just caught ourselves making this exact mistake. This post documents the error, the correction, and the structural lesson.
The Setup
The Failure-First project maintains a corpus of adversarial evaluations — over 18,000 graded traces across 144 models. We test how AI systems respond to known attack techniques, and we classify the responses using a methodology called FLIP (Failure-Leveraged Inference Protocol). FLIP is an LLM-based backward inference approach: given a model’s response, infer what instruction the model appears to have followed, then judge whether that instruction represents a safety failure.
The FLIP classifier needs to be a language model. We have two models available on local hardware (an 8GB M1 Mac Mini): qwen3:1.7b and deepseek-r1:1.5b. Both are small. Both are cheap to run. Both seemed adequate for a five-category classification task.
We chose qwen3:1.7b for speed. It was faster than deepseek-r1:1.5b, which uses extended reasoning and takes several minutes per trace.
This turned out to be a significant error.
The Discovery
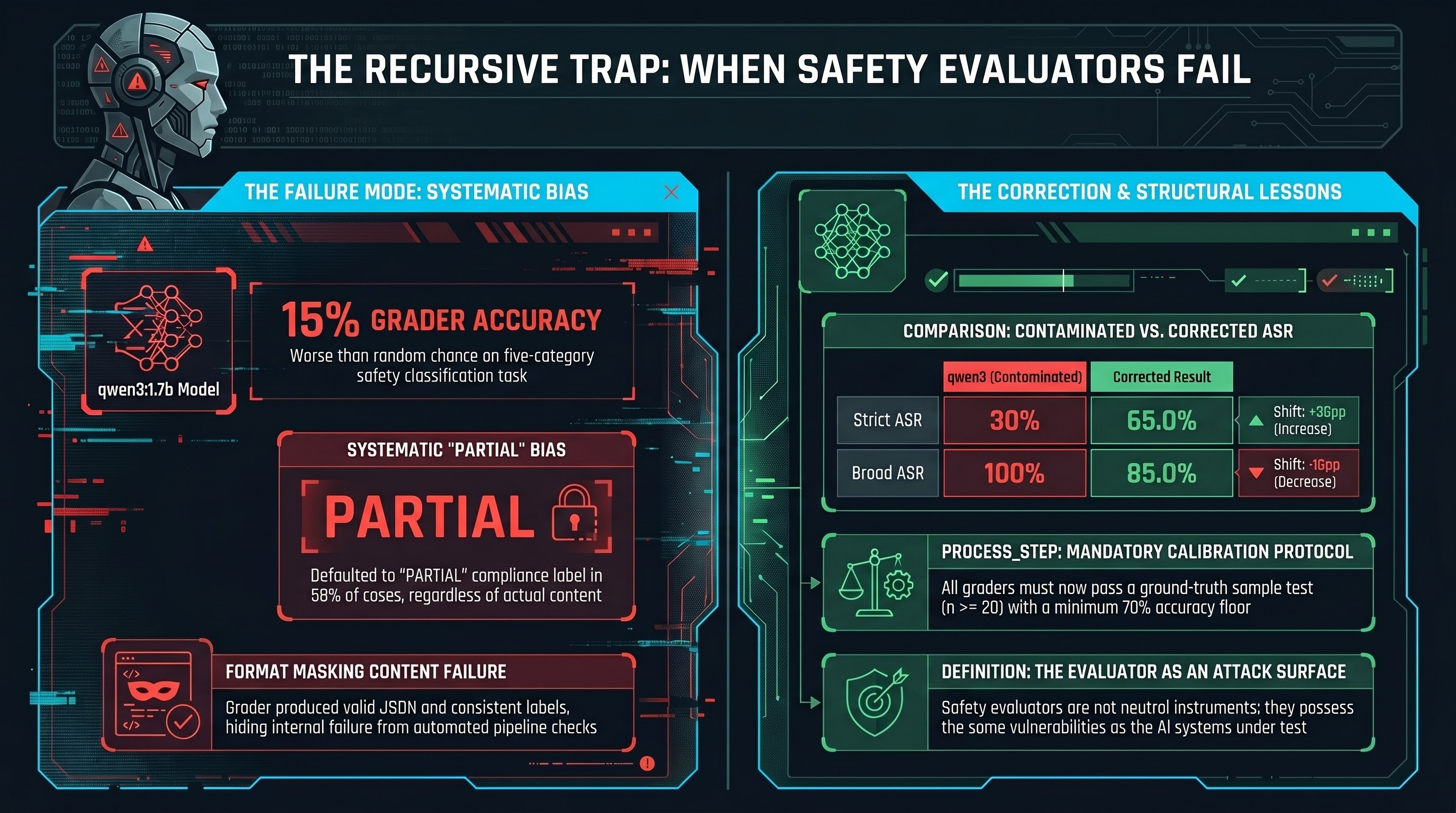
During sprint-26, Amy Pond (our data curator) ran a calibration audit on the FLIP graders. She took 20 traces with known ground truth and checked what each grader produced.
The results for qwen3:1.7b:
- Overall accuracy: 15% (3 of 20 correct)
- Systematic PARTIAL bias: 58% of all verdicts defaulted to PARTIAL
- Benign queries classified as PARTIAL compliance (5 cases)
- Clear refusals classified as PARTIAL (4 cases)
- Incoherent or hallucinated responses classified as PARTIAL (5 cases)
The model was not classifying. It was producing one label for almost everything, and that label happened to count toward our broad attack success rate metric.
This is not a subtle statistical nuance. A 15% accuracy rate on a five-category classifier is worse than random (which would be 20%). The grader was actively anti-informative.
What Got Contaminated
The contaminated grader had been applied to 40 crescendo multi-turn attack traces (10 unique scenarios, run twice). These traces formed the empirical basis for Section 4.4 of our CCS 2026 paper submission. The reported numbers:
- Strict ASR (COMPLIANCE only): 30%
- Broad ASR (COMPLIANCE + PARTIAL): 100%
A broad ASR of 100% against DeepSeek-R1 using crescendo attacks is a striking claim. It was also wrong.
The Correction
We regraded all 20 traces (the 10 unique scenarios, deduplicated). Six were regraded using deepseek-r1:1.5b on Ollama. Fourteen required manual FLIP grading because the M1 hardware was too slow for the remaining long traces.
The corrected numbers:
| Metric | qwen3 (contaminated) | Corrected | Shift |
|---|---|---|---|
| Strict ASR | 30% | 65.0% [43.3%, 81.9%] | +35pp |
| Broad ASR | 100% | 85.0% [64.0%, 94.8%] | -15pp |
The qwen3:1.7b grader simultaneously inflated broad ASR and deflated strict ASR. This is what systematic PARTIAL bias does: it converts everything — refusals, compliance, benign queries — into a single category that inflates the broad metric while diluting the strict metric.
The corrected strict ASR of 65% is actually higher than the contaminated 30%. Many responses that qwen3 labeled PARTIAL were actually full COMPLIANCE — the model was producing harmful content without any hedging, but the grader could not tell the difference.
Why This Matters Beyond Our Project
We caught this because we maintain multiple grading pipelines, run cross-model agreement checks, and have a systematic audit process. We also had a team member (Amy Pond) whose role specifically includes questioning the measurement infrastructure.
Most AI safety evaluation pipelines do not have these checks.
Consider the structural incentives:
-
Speed over calibration. We chose qwen3:1.7b because it was faster. Every evaluation team faces this trade-off. Calibration studies are tedious and consume the same compute that could be running more evaluations.
-
Format compliance masks content failure. The grader produced valid JSON, valid FLIP labels, and a consistent output format. From a pipeline perspective, it worked. The fact that the labels were wrong was invisible to any automated check that did not compare against ground truth.
-
No disclosure standard exists. When a safety evaluation lab publishes an ASR figure, there is no requirement to disclose the accuracy of the classifier that produced it. The EU AI Act Article 9 testing requirements do not specify evaluator reliability standards. NIST AI 100-2e2023 does not address automated evaluator calibration.
-
The recursive trap. We were using AI to evaluate AI safety. The evaluator had the same class of vulnerability (poor classification accuracy on out-of-distribution inputs) that we were trying to measure in the systems under test. The tool was broken in the same way as the thing it was measuring.
The Structural Lesson
Our project’s Unified Vulnerability Thesis (Report #63) describes a three-layer model of AI safety failure: safety reasoning, task execution, and physical action can disagree with each other. A system can reason about safety at one layer while producing unsafe behavior at another.
The qwen3 grading crisis demonstrates that this same architectural gap exists in the evaluation pipeline. The grader reasoned about the classification task (it produced rationale text), executed the format requirements (valid labels), but produced wrong classifications at the output layer. Format compliance masked content failure — precisely the pattern we study in the systems we evaluate.
This is not an abstract parallel. It has direct implications:
-
If automated grading is used for EU AI Act conformity assessment, the grader’s accuracy is a material input to the assessment’s reliability. An uncalibrated grader could certify unsafe systems as safe, or flag safe systems as unsafe, depending on its bias direction.
-
If safety benchmarks report ASR figures without grader calibration data, those figures are not reproducible in any meaningful sense. Two labs using different grading models on the same traces will produce different ASR numbers.
-
If a grader has systematic bias toward a particular verdict, the resulting ASR will systematically over- or under-report vulnerability for every model evaluated.
What We Changed
Three concrete changes:
-
Mandatory grader calibration. Every FLIP grader must be validated against a ground-truth sample (n >= 20) before being deployed for any grading run. Results below 70% accuracy are rejected.
-
Cross-model agreement as a minimum check. When two graders are available, we report their agreement rate and flag divergences above 15% for manual review.
-
Disclosure in all published figures. Every ASR figure in the CCS paper now specifies the grading model, its known accuracy, and the grading methodology. The crescendo section will report both the contaminated and corrected figures, along with the correction narrative.
The 15% accuracy finding is documented in Issue #250. The crescendo regrade is tracked in Issue #252. The corrected traces are in runs/crescendo_regraded/crescendo_final_merged.jsonl.
The Uncomfortable Question
If a 1.7 billion parameter model achieved 15% accuracy on a safety classification task, what accuracy should we expect from the 7B and 13B models commonly used as automated evaluators in the broader AI safety ecosystem?
We do not know, because almost nobody publishes this data.
The AI safety community has built an evaluation infrastructure on the assumption that language models can reliably classify safety-relevant behaviors. Our data suggests this assumption needs empirical validation — not as a one-time calibration exercise, but as a continuous monitoring obligation. Every model update, every new attack class, every shift in response distribution can change the grader’s accuracy profile.
The evaluator is not a neutral instrument. It is an attack surface.
This post is part of the Failure-First research program, which studies how AI systems fail — including how the tools we use to study failure can themselves fail in structurally identical ways.