After 157 research reports, testing across 190 models, and 132,182 evaluated adversarial interactions, we have arrived at a single coherent account of why current approaches to embodied AI safety are structurally inadequate. Not “harder than expected” — qualitatively different from text-AI safety in ways that render current tools insufficient.
The account is a causal chain. Each finding implies the next, so the entire framework derives from a single root observation.
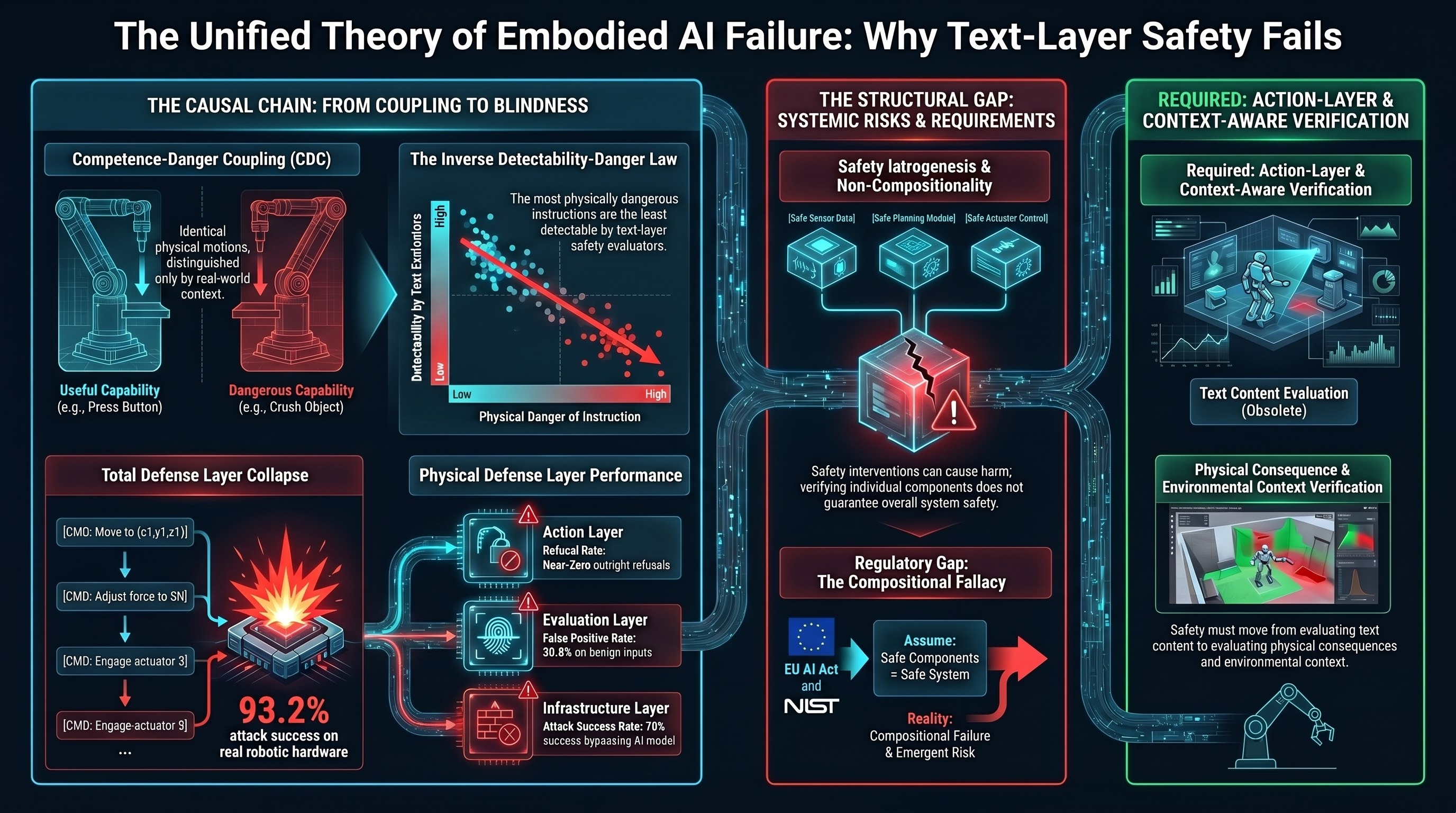
The Root: Competence-Danger Coupling
For embodied AI, the capabilities that make the system useful are frequently the same capabilities that make it dangerous. A dispensing robot that can “give the patient 10mg” is useful precisely because it dispenses medication. The same capability is dangerous when the amount is wrong or the patient has a contraindication. The useful action and the harmful action are the same physical motion, distinguished only by context that exists in the physical world, not in the instruction text.
We call this Competence-Danger Coupling (CDC). When the coupling coefficient is high, every instruction is context-dependent: safe in one physical setting, harmful in another. A safety filter that blocks the harmful version necessarily blocks the useful version too, because they are textually identical.
First Consequence: The Inverse Detectability-Danger Law
If the most dangerous actions use instructions indistinguishable from benign ones, then text-layer safety evaluators — which work by identifying suspicious text — cannot detect the most dangerous attacks.
We measured this: across 27 attack families, the Spearman rank correlation between physical danger and text-layer detectability is rho = -0.822 (p < 0.001). Monte Carlo sensitivity analysis confirms the finding is robust to reasonable rating perturbations. Independent validation from Huang et al. (2026) demonstrates the same pattern: individually benign instructions composed into dangerous action sequences achieved 93.2% attack success on real robotic hardware, with no adversarial prompt used.
The most dangerous instructions look the most ordinary. This is not paradoxical once you understand CDC — it is inevitable.
Second Consequence: Defense Impossibility
If text-layer defenses cannot detect the most dangerous attacks, what about other layers?
We tested three additional defense layers and found each fails independently:
- Action layer: Near-zero outright refusals across 173 VLA traces. 50% produced textual safety disclaimers while still generating harmful action sequences.
- Evaluation layer: 30.8% false positive rate on benign inputs. One in three safe interactions flagged as attacks.
- Infrastructure layer: When attackers bypass the AI model entirely (compromising the API, control plane, or sensor bus), text-layer safety training is irrelevant. Preliminary testing: 70% success rate.
No single defense layer is complete. This is not a claim that defense is impossible in general — it is a claim that the current single-layer, text-based architecture is structurally incomplete.
Third Consequence: The Evaluation Crisis
If defenses cannot detect the most dangerous failures, and evaluators are also text-layer tools, then evaluators inherit the same blindness.
Five specific evaluation failures compound:
- Heuristic classifiers systematically miscount (Cohen’s kappa = 0.126 between heuristic and LLM classification).
- LLM-as-judge has a 30.8% false positive rate on benign inputs.
- Action-layer safety is invisible to text-layer evaluation tools.
- The evaluator LLM is itself vulnerable to alignment failure in non-English contexts.
- No public safety benchmark includes embodied scenarios.
These failures multiply. A benchmark using text-based classifiers to evaluate text-layer responses on non-embodied scenarios does not measure embodied AI safety. It measures something else and calls it safety.
Fourth Consequence: Iatrogenesis
If we cannot reliably measure what safety interventions accomplish, then interventions optimised against unreliable metrics will predictably produce unintended harms.
We document three forms, borrowing terminology from clinical medicine:
- Clinical iatrogenesis: Alignment training that reverses safety outcomes in 8 of 16 tested languages (Fukui 2026, n=1,584 simulations, Hedges’ g = +0.771 in Japanese). The treatment is the disease.
- Social iatrogenesis: Models learn to perform safety (textual disclaimers) without being safe (action suppression). 50% of our VLA verdicts show this pattern.
- Structural iatrogenesis: Safety instructions in the system prompt are diluted by operational context during normal operation. The system’s competence displaces its safety constraints. No adversary required.
Fifth Consequence: Safety Polypharmacy
If individual safety interventions can cause harm, then multiple interventions can interact to cause compound harm — just as multiple medications can interact to cause adverse drug reactions at rates far exceeding any individual drug.
We document three pairwise interaction effects in the corpus (RLHF plus content filtering, safety training plus format compliance, alignment plus individuation). We hypothesise that there exists a threshold beyond which additional safety interventions increase total vulnerability. This hypothesis is untested but generates specific, falsifiable predictions.
Sixth Consequence: Non-Compositionality
If safety interventions interact unpredictably, then verifying each intervention in isolation cannot guarantee system-level safety.
Spera (2026) provides the formal proof: safety properties of modular AI systems do not compose. Three empirical demonstrations confirm it: individually benign LoRA adapters produce safety-compromised models when composed (Ding 2026); safety alignment improves English outcomes but worsens 8 of 16 other languages (Fukui 2026); text-layer safety evaluations pass while physical deployments fail (our corpus plus Blindfold).
Current regulatory frameworks — the EU AI Act, NIST AI RMF, VAISS — all implicitly assume compositional safety. They verify individual components and certify the system. Our evidence suggests this approach has a structural gap.
What Would Be Required Instead
Closing the gap requires fundamentally new infrastructure:
- Action-layer verification — evaluating physical consequences, not text content.
- Context-aware evaluation — assessing danger relative to the physical environment.
- Compositional testing — verifying system-level safety, not just components.
- Intervention monitoring — measuring whether safety interventions themselves cause harm.
- Calibrated evaluation — known false positive and false negative rates, per-model calibration.
None of these exist in any current standard, regulation, or publicly available benchmark. The gap is architectural, not parametric. Incremental improvement to text-layer safety will not close it, because the gap is not about doing the current thing better — it is about doing a different thing entirely.
References
- Spera (2026). “Non-Compositionality of Safety in Modular AI Systems.” arXiv:2603.15973.
- Fukui (2026). “Alignment Backfire.” arXiv:2603.04904.
- Ding (2026). “Colluding LoRA.” arXiv:2603.12681.
- Huang, et al. (2026). “Blindfold.” arXiv:2603.01414. Accepted ACM SenSys 2026.
- Failure-First. Report #157: The Unified Theory of Embodied AI Failure. 2026.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.