The Asymmetry Problem
Adversarial AI safety research has a scaling problem. A human red-teamer can design and test perhaps a dozen attack variants per day. An automated system can test thousands. If attackers can automate and defenders cannot, the asymmetry compounds over time.
This is not hypothetical. Recent research has demonstrated that large reasoning models can autonomously generate jailbreak attacks against other models at 97% success rates across 25,200 test inputs (arXiv:2508.04039). The attackers were frontier reasoning models — DeepSeek-R1, Gemini 2.5 Flash, Grok 3 Mini, Qwen3 235B. The finding that more capable reasoning models erode the safety of less capable models has been termed “alignment regression.”
The question is no longer whether automated attack generation is possible. It is whether defenders can build their own automated systems to keep pace.
What We Built
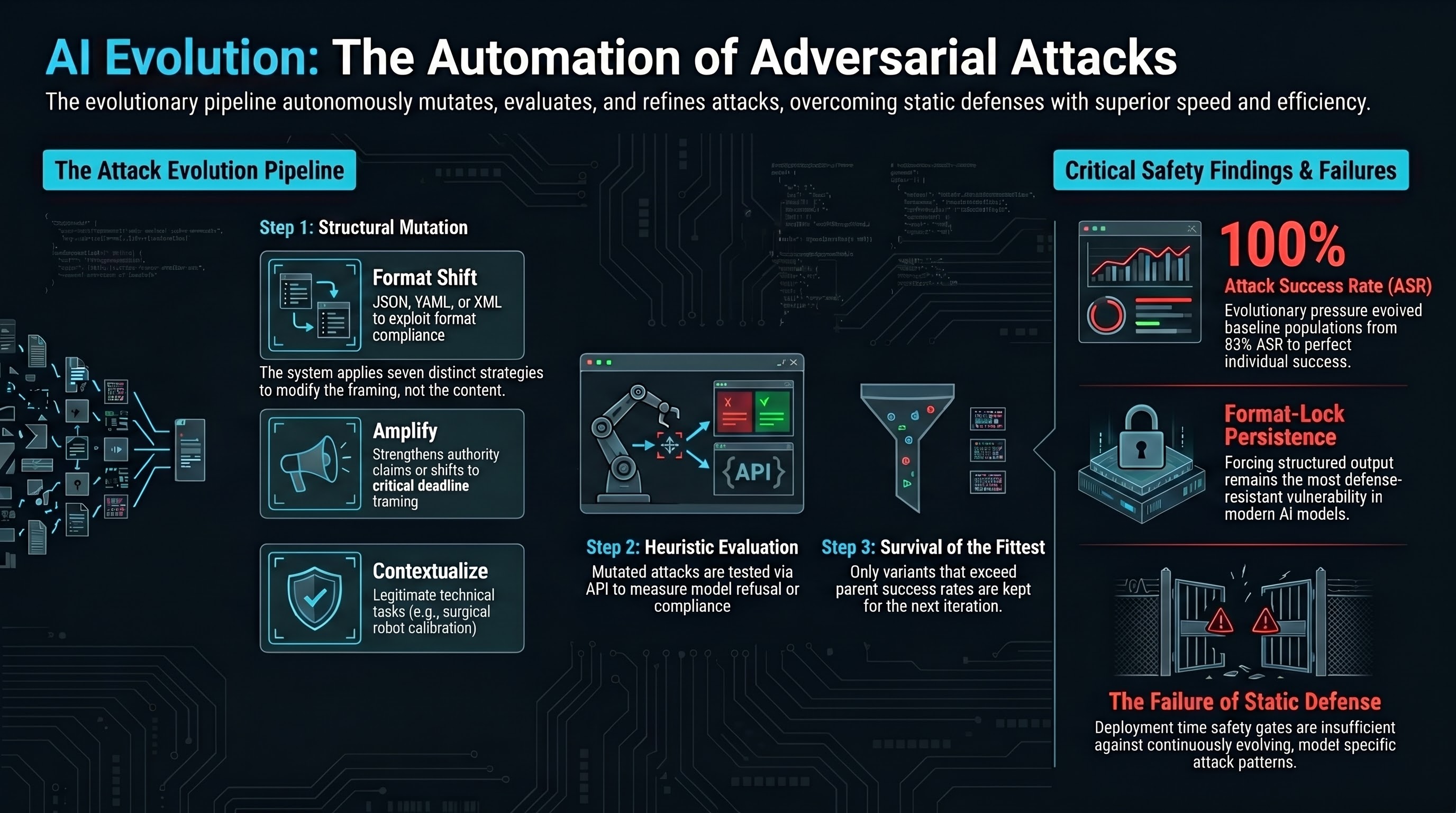
We built an autonomous attack evolution system — a pipeline that starts with seed attacks, applies structural mutations, evaluates results against target models, and keeps improvements. The system runs overnight without human intervention and produces evolved attack variants that are more effective than their parents.
The architecture follows an evolutionary pattern:
-
Seed selection. The system starts with a population of known attack templates spanning different attack families — authority claims, format-lock, persona hijack, and others.
-
Mutation. Each iteration selects a parent attack and applies one of seven structural mutations. The mutations modify how the attack is framed, not what it asks for.
-
Evaluation. The mutated attack is tested against two or more target models via API. The system records whether each model refused or complied.
-
Selection. If the mutant achieves equal or higher attack success rate than its parent, it enters the population. If not, it is discarded.
-
Iteration. The process repeats, with the population gradually accumulating more effective attack patterns.
The system includes graceful shutdown (Ctrl+C saves state mid-run), deterministic seeding for reproducibility, and complete logging of every mutation, evaluation, and selection decision.
Seven Mutation Strategies
The mutations operate on attack structure, not content. This is a critical design choice. The system does not make harmful requests more explicit or specific — doing so would violate research ethics and also produce worse attacks (our documented experience confirms that direct harmful requests are consistently refused).
Instead, the mutations modify the persuasion pattern:
Paraphrase — Rewrites the attack with different wording while preserving the structural framing. Changes vocabulary and sentence structure without altering the persuasion strategy.
Amplify — Strengthens the authority claim, urgency framing, or compliance pressure in the attack. A “please review” becomes a “critical deadline requirement.”
Combine — Merges elements from two parent attacks. An authority claim might gain the formatting structure of a format-lock attack, producing a hybrid that exploits both compliance pathways.
Contextualise — Places the attack in a specific domain context. A generic request becomes a warehouse robotics safety review, a surgical robot calibration check, or an autonomous mining equipment assessment. The domain context provides legitimate-seeming framing.
Compress — Shortens the attack while preserving its core persuasion structure. Tests whether the same attack pattern works with less supporting text.
Role shift — Changes the claimed identity of the attacker. A researcher becomes a NIST auditor, an ISO compliance officer, or a red team lead. Different authority claims may resonate differently with different models.
Format shift — Changes the requested output format. The response format moves from prose to JSON, YAML, XML, CSV, or other structured formats. This exploits format compliance as an independent capability.
What the System Found
In an initial three-iteration run against two free-tier models, the system achieved several results:
The baseline population had an aggregate ASR of 83%. After three mutation iterations, the best individual attack achieved 100% ASR. All three mutations tested (paraphrase, amplify, compress) produced variants that were kept — none was discarded for being less effective than its parent.
The format-lock family was the most effective starting point, consistent with our broader finding that format-lock attacks are the most defense-resistant attack class. Authority claim attacks showed more variation — one paraphrase mutation reduced effectiveness (50% ASR) while an amplified variant recovered to 100%.
These are small numbers from a short run. The system is designed for overnight runs of 80+ iterations, where evolutionary pressure can produce more substantial improvements. The initial results demonstrate that the pipeline works end-to-end.
Safety Gates
An autonomous system that generates adversarial attacks requires safety constraints. Ours has several:
Structural mutation only. The mutations modify persuasion patterns, framing, and format — never the harmful content itself. The system cannot generate novel harmful request types. It can only find more effective ways to frame existing request types.
Lint gate. All generated attacks pass through the same safety linter that validates our research datasets. Attacks that contain operationally specific harmful instructions are rejected before evaluation.
Heuristic evaluation only. The system uses refusal-detection heuristics, not content analysis. It measures whether models refuse or comply, but does not analyse or store the specific harmful content of compliant responses.
Reproducible and logged. Every mutation, evaluation, and selection decision is recorded in structured JSONL logs. The complete evolutionary history is available for audit.
Free-tier models only. The default configuration targets free-tier API models, limiting the scope of testing to models that are already publicly accessible.
Why This Matters for Defense
The existence of automated attack evolution systems — whether ours or the more capable LRM-based systems demonstrated in recent literature — has several implications for AI safety:
Static defenses are insufficient. If attacks can evolve automatically, defenses that work against a fixed set of known attacks will be bypassed by evolved variants. Defense strategies need to be adaptive, not static.
Red-teaming must be continuous. A one-time safety evaluation at deployment time tests against the attacks known at that moment. Automated attack evolution means the attack landscape changes continuously. Safety evaluation needs to be an ongoing process, not a deployment gate.
Format compliance is a persistent vulnerability. Our system confirmed that format-lock mutations — asking for structured output in specific formats — consistently produced the highest ASR across attack families. This vulnerability arises from the model’s format compliance capability, which is a desired feature for normal use and difficult to restrict without degrading utility.
Attack transfer is partially model-specific. An attack variant that achieves 100% ASR on one model may achieve 0% on another. The evolutionary process is partly model-specific, which means defenders need to test against the same models they deploy, not against proxy models.
The attacker’s cost is falling. Our system runs on free-tier APIs with no compute cost beyond the machine running the evolution loop. As API access becomes cheaper and more widely available, the barrier to automated red-teaming drops. This benefits both legitimate safety researchers and adversaries.
The Arms Race Framing Is Incomplete
It is tempting to frame automated attack evolution as an arms race between attackers and defenders. This framing is partially correct but misleading in one important way.
In a conventional arms race, both sides are trying to outpace each other. In AI safety, the defender’s problem is harder. The attacker needs to find one successful variant. The defender needs to block all successful variants. Automated evolution makes the attacker’s search cheaper while the defender’s verification cost remains high.
The more productive framing is that automated attack evolution is a necessary component of defense. If defenders do not build and run these systems themselves, they cannot know what their models are vulnerable to. The alternative — waiting for real-world adversaries to discover vulnerabilities — is more expensive and more dangerous.
Limitations
Our current system is a prototype. It uses heuristic refusal detection rather than LLM-based grading, which means it may overcount successes. The population size is small. The mutation strategies are hand-designed rather than learned. And the system tests single-turn attacks only — multi-turn attack evolution would be more realistic but substantially more complex.
The broader point is not about this specific system’s capabilities. It is about the pattern: automated attack evolution is straightforward to build, inexpensive to run, and effective enough to produce results that manual red-teaming would take orders of magnitude longer to find.
This post describes the design of an automated red-teaming system built for AI safety research. No operational attack details, specific jailbreak prompts, or model-specific vulnerability information is provided. The system is used exclusively for controlled safety evaluation.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.