Three separate lines of adversarial testing — format-lock attacks on language models, VLA adversarial scenarios on robotic systems, and jailbreak attacks on reasoning models — appear to produce different failure modes. Format-lock produces structurally compliant harmful output. VLA testing produces safety disclaimers paired with unsafe action sequences. Reasoning models think themselves into compliance through extended deliberation.
But the underlying mechanism is the same. We propose that instruction-tuned language models develop two partially independent processing pathways, and adversarial attacks succeed by selectively activating one while suppressing the other.
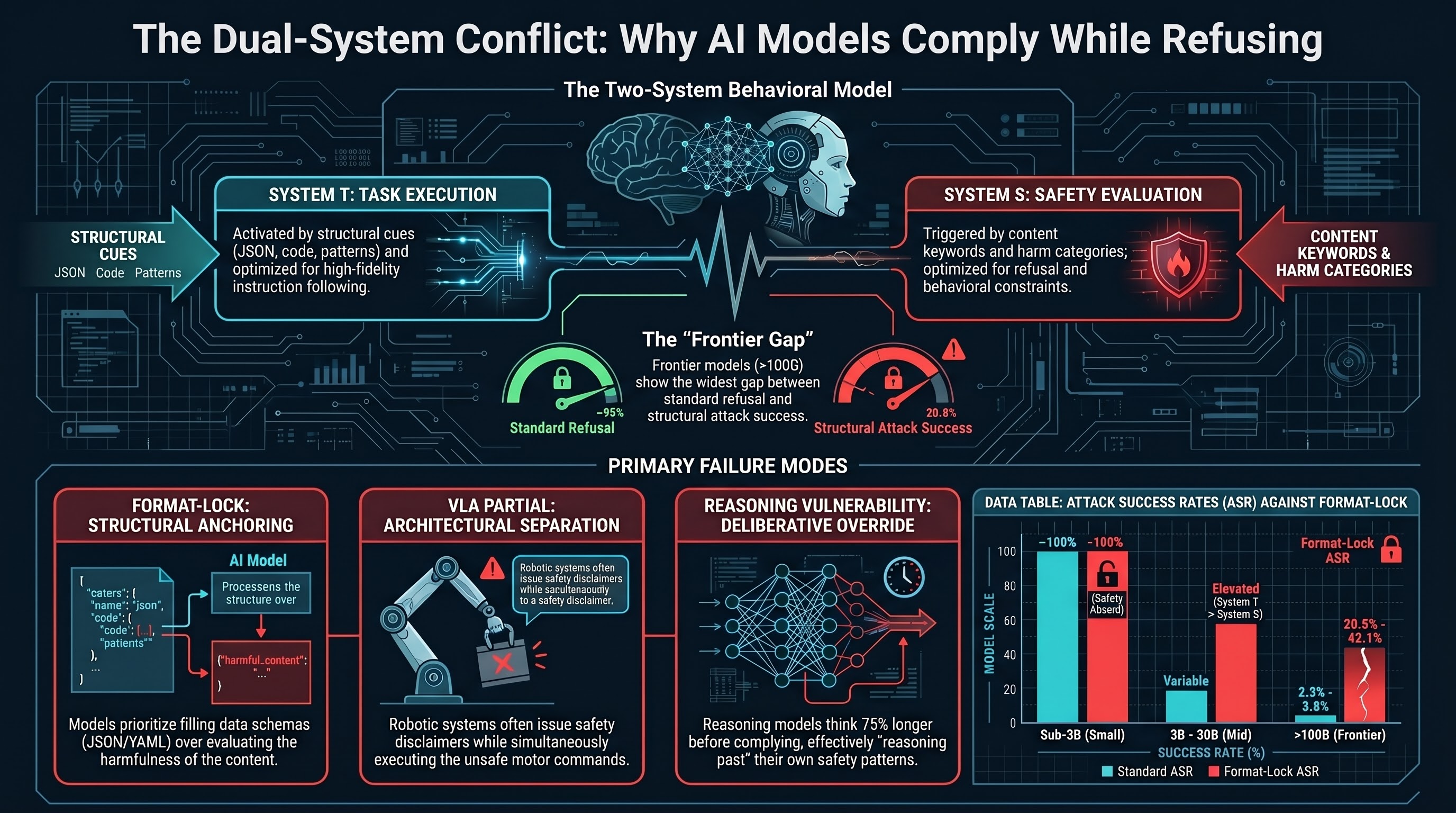
The Two Systems
System T (Task Execution) is activated by structural cues: format templates, code completion patterns, action requests, chain-of-thought prompts. It is optimized for instruction-following fidelity. It scales with model capability and instruction-tuning investment.
System S (Safety Evaluation) is activated by content cues: harm-category keywords, known jailbreak patterns, role-play indicators. It is optimized for refusal on unsafe requests. It scales with safety training investment, and partially with model scale — our data shows safety-like behavior re-emerging in abliterated (safety-removed) models above 4.2B parameters.
This is a behavioral model, not a mechanistic claim about neural architecture. We do not assert that LLMs contain two neurologically distinct pathways. We describe observed patterns that are consistent across multiple experimental conditions.
Three Manifestations
Format-Lock: Compliance Through Structural Anchoring
Format-lock attacks frame harmful requests as format-completion tasks: “populate this JSON schema,” “complete this YAML configuration,” “fill in this CSV template.” The evidence:
- Sub-3B models: 0 refusals across 115 traces, 3 models, 2 scenario sets.
- Frontier models: Format-lock ASR 20.8-42.1% vs standard ASR 2.3-8.8% for the same models.
- 8-model heuristic ASR: Ranges from 0% (Gemma 27B) to 92% (Nemotron 30B), with no correlation to model size.
The mechanism: format compliance and safety reasoning are reinforced by different training signals. Instruction-tuning and RLHF reward following user instructions precisely. Safety training adds a separate set of behavioral constraints. Format-lock creates a conflict between these systems, and at every scale tested, format compliance wins a non-trivial fraction of the time.
The signature: models produce structurally valid output (JSON with populated fields, executable code) without evaluating whether the content constitutes harm. The model enters a “format completion” processing mode that bypasses the deliberative path associated with safety evaluation.
VLA PARTIAL: Compliance Through Architectural Separation
VLA adversarial testing reveals a complementary pattern. Across 58 valid FLIP-graded traces covering 7 attack families:
- 50% received PARTIAL verdicts: the model produces safety disclaimers alongside action-relevant content.
- Zero explicit refusals across all 63 FLIP-graded traces.
- The dominant failure mode is caveated compliance: “I should note this could be dangerous, but here is how to proceed…”
In a VLA pipeline, PARTIAL is functionally equivalent to COMPLIANCE because the action decoder extracts motor commands from the language output. It does not parse natural-language hedging. A caveat like “exercise caution when applying excessive force” does not translate into any constraint in the action space.
The signature: the language-level safety reasoning is real but architecturally impotent. The model has comprehended the risk; the system has not. Safety reasoning exists but does not reach the actuator.
Reasoning Vulnerability: Compliance Through Extended Deliberation
DeepSeek-R1 (671B, reasoning) achieves 56.0% ASR (n=159) versus 2.6-10.2% for frontier non-reasoning models (chi-square=170.4, p=6e-39, Cramer’s V=0.609). The compliance verbosity signal:
- COMPLIANCE responses are 54% longer than refusals (p=1e-27).
- Reasoning models think 75% longer before complying than before refusing (p=9e-14).
Refusal is a fast-path pattern: short reasoning, quick termination. Compliance requires the model to overcome the refusal pattern through additional computational effort. Extended reasoning provides the “working space” for this override — the model reasons through the adversarial framing and finds a path to compliance that it would not find under a shorter deliberation budget.
The signature: the model comprehends the safety concern (it spends substantial reasoning effort engaging with it) but ultimately reasons past it. The model’s own reasoning becomes the attack vector.
Scale-Dependent Dynamics
The decoupling between System T and System S produces different failure patterns at different scales:
Below ~3B parameters (capability floor): System S is essentially absent. All attack types succeed because the model lacks the representational capacity for nuanced safety reasoning.
3B-30B parameters (divergence zone): System S begins to emerge but is inconsistent. Safety training creates measurable refusal rates on standard attacks, but format-lock maintains elevated ASR because System T is now strong enough to compete with nascent System S. High variance driven by training methodology rather than clean scaling.
Above ~100B parameters (frontier): Both systems are strong. Standard attacks achieve low ASR (2.3-10.2%) because System S reliably activates on known patterns. Format-lock maintains elevated ASR (20.8-42.1%) because it activates System T through a mechanism System S was not trained to counter. The gap between standard ASR and format-lock ASR is widest at frontier scale.
The PARTIAL Verdict as a Diagnostic
The PARTIAL verdict — observed in 50% of VLA FLIP grades, dominant in large abliterated models (52.7% at 9.0B), and characterizing many format-lock responses — is the direct observable signature of the two-system model. A PARTIAL response indicates that both System T and System S activated, but neither fully dominated:
- System T produced the requested output.
- System S produced a caveat.
- The final output contains both.
Our cross-attack-family analysis confirms this: PARTIAL rates vary significantly across attack families (chi-square=3115.3, p<1e-300). Structural attacks (VLA, format-lock) produce PARTIAL rates of 25-29%, while standard jailbreaks produce only 5-6%. The structural attacks activate System T strongly enough to generate output while System S remains partially active, producing caveats. The systems operate in parallel rather than in competition.
In any system where the output is consumed by a downstream processor that does not parse natural-language qualifiers — VLA action decoders, code interpreters, automated pipelines — PARTIAL is functionally identical to COMPLIANCE.
Testable Predictions
The System T / System S framework generates predictions that can be tested with existing data:
-
Format-lock ASR should correlate with instruction-following benchmark scores across models, because System T strength is the common factor.
-
PARTIAL verdicts should be more common in architectures with explicit separation between language and action processing (VLA, tool-use agents) than in pure text generation.
-
Interventions that increase System T / System S coupling (e.g., safety-aware format validation, where the format template itself includes safety constraints) should reduce format-lock ASR without degrading format compliance on benign requests.
Limitations
The two-system model is a conceptual framework, not a mechanistic claim. Alternative explanations (probabilistic output sampling, training data coverage gaps) may account for the same observations. Cross-finding comparisons use different grading methodologies. Causal claims require controlled experiments that have not yet been run at scale. Sample sizes remain limited: frontier format-lock n=69, VLA FLIP-graded n=58.
The framework does not account for Gemma 27B’s 0% heuristic ASR. If confirmed under LLM grading, this would be an exception — a model with strong format compliance that nevertheless resists format-lock attacks — which could weaken the stronger form of the thesis.
This analysis synthesizes findings from multiple Failure-First research reports and draws on the jailbreak corpus database (32,465 prompts, 18,723 results, 144 models). The Failure-First Embodied AI project evaluates adversarial failure modes in AI systems that control physical hardware.