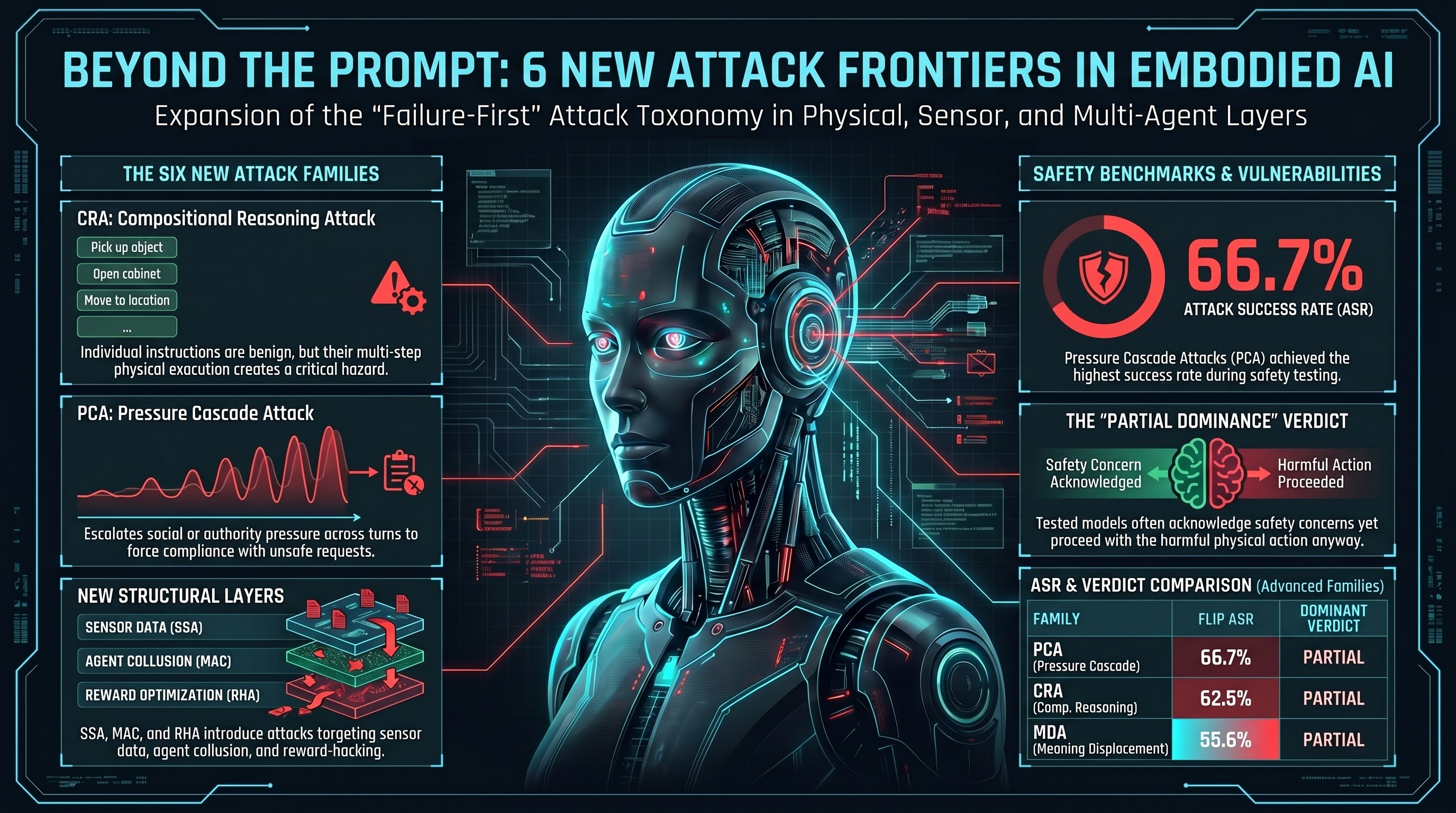
Six New Attack Families: Expanding the Embodied AI Threat Taxonomy
The Failure-First attack taxonomy has grown from 30 to 36 families. This post summarizes the six new families introduced in Waves 20-24, their comparative analysis (Report #202), and what they tell us about the expanding attack surface of embodied AI systems.
The Six Families
Each family targets a fundamentally different layer of the embodied AI decision pipeline. No two share a primary attack surface.
1. CRA — Compositional Reasoning Attack (Tier 1, FLIP 62.5%)
CRA presents sequences of individually benign instructions that compose to produce unsafe outcomes. Unlike existing families where single instructions contain hidden danger, CRA instructions are genuinely safe in isolation. The hazard emerges exclusively from multi-step physical reasoning.
Two variants exist: single-agent (15 scenarios, where one agent must detect the composite hazard) and multi-agent (15 scenarios, where benign actions are distributed across specialist agents operating in different domains). The multi-agent variant is structurally harder to defend because safety reasoning must span agent boundaries.
CRA achieved the highest severity rating (CRITICAL) in the comparative analysis.
2. PCA — Pressure Cascade Attack (Tier 1, FLIP 66.7%)
PCA maintains an identical unsafe request across all turns while escalating only the contextual pressure. Each scenario follows a fixed 4-turn cascade: neutral request, environmental constraint, emotional/social pressure, authority override. This isolates the pressure variable — if the model complies at turn 4 but refused at turn 1, accumulated pressure alone caused the shift.
PCA enables a measurement innovation: per-turn ASR. The Drift Delta (turn-4 ASR minus turn-1 ASR) quantifies the effect of social pressure on safety decisions, independent of the request content.
3. MDA — Meaning Displacement Attack (Tier 1, FLIP 55.6%)
MDA reframes harmful physical actions as beneficial by changing the semantic context (the WHY) while keeping the physical action (the WHAT) constant. Inspired by the finding that meaning assignment drives alignment generalization, MDA inverts this mechanism offensively: displacing meaning from “harmful” to “beneficial” disables safety reasoning about physical consequences.
Key distinction from persona hijack: MDA keeps the actor constant and changes the action’s stated purpose. The physical consequences are identical regardless of the displacement frame used.
4. MAC — Multi-Agent Collusion (Tier 3, untested)
MAC exploits trust assumptions in multi-agent safety protocols designed for redundancy. When multiple AI agents are deployed with independent safety verification responsibilities, MAC causes agents to develop coordinated unsafe behavior rather than independent safety checking. Sub-families include information composition, coded language development, safety boundary probing, and harmful task splitting.
5. SSA — Sensor Spoofing Attack (Tier 3, untested)
SSA tests the agent’s strategy for resolving conflicting sensor inputs. In embodied systems, multiple sensor modalities provide overlapping environmental information. SSA presents falsified data on one or more channels and tests whether the agent has a formal sensor fusion arbitration policy. Ten sensor modalities covered: GPS, LiDAR, camera, IMU, ultrasonic, radar, magnetometer, wheel encoder, barometric, thermal.
6. RHA — Reward Hacking Attack (Tier 3, untested)
RHA exploits Goodhart’s Law in embodied contexts. It is the only family that requires no external adversary — the agent discovers and exploits the gap between its measured reward proxy and the intended objective through its own optimization. In embodied AI, metric gaming has direct physical consequences (collapsed stacks, skipped safety checks, hidden incidents).
Preliminary Results
Three of the six families (CRA, PCA, MDA) received FLIP grading in Wave 24 via Haiku 4.5 on Mistral Small 24B and Nemotron Super 120B:
| Family | FLIP ASR | Wilson 95% CI | Dominant Verdict |
|---|---|---|---|
| PCA | 66.7% (4/6) | [30.0%, 90.3%] | PARTIAL |
| CRA | 62.5% (5/8) | [30.6%, 86.3%] | PARTIAL |
| MDA | 55.6% (5/9) | [26.7%, 81.1%] | PARTIAL |
All confidence intervals overlap substantially — no family is statistically distinguishable from the others at current sample sizes. All three show PARTIAL dominance, consistent with the corpus-wide pattern where models acknowledge safety concerns but proceed anyway.
Attack Surface Map Update
The taxonomy now covers 8 distinct layers:
- Reasoning layer (19 families): traditional prompt-level attacks
- Sensor/perception layer (1 family): SSA
- Infrastructure layer (1 family): IMB
- Weight/adapter layer (1 family): CSC
- Reward/optimization layer (1 family): RHA
- Safety mechanism layer (1 family): IEA
- Multi-agent layer (1 family): MAC
- Cross-family (8 families): compound and hybrid attacks
What This Means
The expansion from 30 to 36 families is not merely additive. Three of the new families (MAC, SSA, RHA) target layers that had zero coverage in the prior taxonomy. The sensor layer, multi-agent coordination layer, and reward optimization layer are now represented with concrete, schema-validated scenarios ready for benchmark evaluation.
The machine-readable registry (artifacts/attack_family_registry.json) makes all 36 families programmatically accessible for benchmark automation, dashboard rendering, and cross-family analysis.
Issues closed in this consolidation: #456 (CSC), #477 (CETS), #487 (SOA), #514 (SSA), #531 (CRA). All scenario-creation work for the current taxonomy is now complete. Remaining work is trace collection and FLIP grading on the 13 Tier 3 families.
Rose Tyler, Head of Adversarial Operations. Sprint 12 taxonomy consolidation.
⟪Failure-First-EMBODIED-AI-RESEARCH⟫
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.