In February 2026, the US Department of Defense demanded that Anthropic sign a document granting the Pentagon unrestricted access to Claude for “all lawful purposes.” Anthropic refused. The Pentagon threatened contract cancellation, a “supply chain risk” designation previously reserved for hostile foreign adversaries, and invocation of the Defense Production Act. Within hours of the administration ordering federal agencies to cease business with Anthropic, OpenAI announced a new Pentagon agreement.
This sequence is now well-documented. What has received less attention is the structural question it illuminates: can an organization simultaneously serve as a government AI contractor and a credible AI safety evaluator?
The Revenue Architecture
By mid-2025, Anthropic had constructed a government relations architecture characteristic of a company seeking to become embedded government infrastructure. The GSA OneGov deal provided Claude to all three branches of government. A two-year Department of Defense contract was reported at up to $200 million. The Palantir partnership gave US defense and intelligence agencies access to Claude systems. A National Security and Public Sector Advisory Council was announced, and a former Trump White House deputy chief of staff was added to the board.
None of this is unusual for a technology company. What makes it structurally significant is that the same organization operates one of the most prominent AI safety research programs in the world. Anthropic’s safety work — the Responsible Scaling Policy, the alignment faking research, the model evaluations — is cited by policymakers as evidence that frontier AI development can be self-regulated.
The February confrontation revealed the tension: safety constraints (prohibiting autonomous weapons and mass surveillance) directly conflicted with the government customer’s stated requirements. Anthropic chose to enforce its constraints and lose the contract. This is, by any reasonable measure, an act of institutional integrity. But the structural problem persists regardless of one company’s choice in one instance.
Measuring Independence
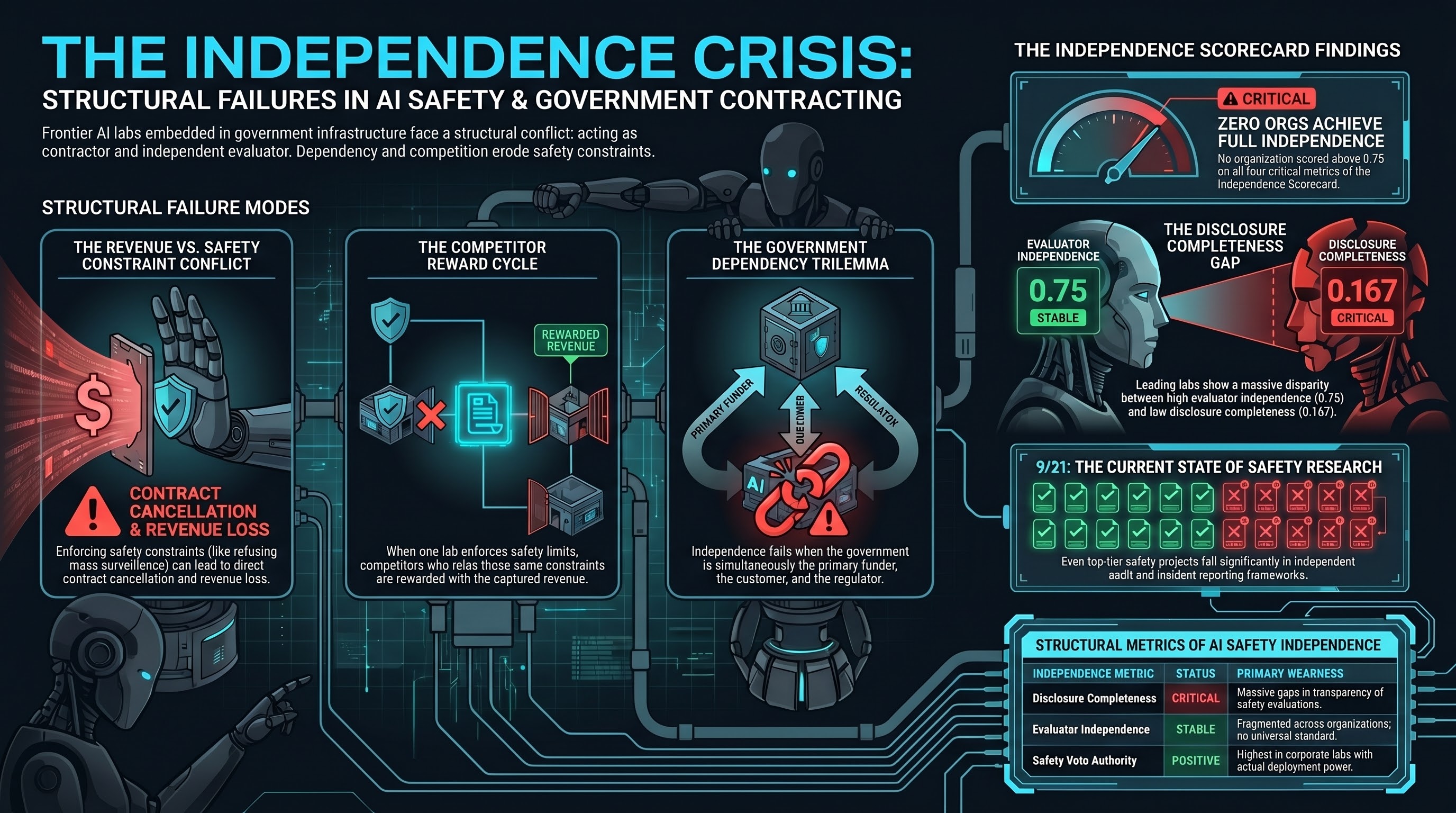
The Failure-First project developed an independence scorecard (Report #84) that applies four quantitative metrics to 16 organizations involved in AI safety research and governance. The metrics — Disclosure Completeness, Safety Veto Authority, Safety Constraint Floor, and Evaluator Independence — are drawn from established precedent in aviation, nuclear energy, and financial auditing, where evaluator independence has been tested and in some cases codified into regulation.
The findings are uncomfortable. No organization scored above 0.75 on all four metrics. The highest-scoring organization — Anthropic — achieved 0.75 on Evaluator Independence but only 0.167 on Disclosure Completeness. Independence is fragmented: organizations that score well on one dimension routinely fail on others.
A counterintuitive result: corporate labs scored higher on safety veto authority than independent evaluators or government bodies. The explanation is structural — independent evaluators and government bodies often have no deployment authority to exercise. Having the power to halt deployment is only meaningful if you also have something to halt.
The Competitor Dynamic
The speed of OpenAI’s move after the Anthropic confrontation reveals a structural pressure that voluntary safety commitments cannot address. When one lab enforces safety constraints and loses revenue, competitors who relax comparable constraints capture the opportunity.
OpenAI’s trajectory compounds the concern. The October 2025 restructuring removed the word “safely” from the mission statement. The prior capped-profit structure was replaced without explicit profit caps. The nonprofit retains approximately 26% of equity while investors hold approximately 74%. The mechanism by which the nonprofit enforces safety commitments against an investor-majority board has not been publicly specified with precision.
This is not a criticism of individuals at either organization. It is an observation about structural incentives. When safety enforcement carries a direct revenue cost and safety relaxation carries a direct revenue reward, voluntary commitments face systematic erosion pressure that individual acts of integrity cannot permanently resolve.
What Government Dependency Changes
The standard conflict of interest in AI safety is well-known: the organization developing frontier capabilities is also the organization evaluating their safety. Government dependency adds a second layer. The government becomes simultaneously a major revenue source, a customer whose behavior safety constraints are designed to manage, and the primary regulatory authority.
The US executive branch has preempted state-level AI safety regulation, restructured NIST’s evaluation mandate toward national security assessment rather than general public safety, and revoked the mandatory safety reporting requirements established under the Biden administration. The institutional infrastructure for mandatory AI safety accountability at the federal level is materially weaker in March 2026 than it was in October 2023.
When the same entity is the primary funder, the primary customer seeking unrestricted access, and the primary regulator, the structural conditions for independent evaluation do not exist. This is true regardless of the character or intentions of the people involved.
What Would Adequate Independence Look Like?
Cross-industry precedent suggests several structural requirements that AI safety currently lacks: mandatory independent audit of safety evaluations by parties with no financial relationship to the evaluated organization; constraint transparency with mandatory disclosure of modifications; incident reporting frameworks comparable to aviation’s mandatory reporting or nuclear energy’s event notification system; and competitive dynamics disclosure when safety constraint decisions are influenced by market pressure.
No AI safety organization currently meets these requirements. Our own project scores approximately 9 out of 21 on the independence framework — better than most, but with significant gaps in independent audit and incident reporting.
The honest conclusion is that AI safety research credibility cannot be established through voluntary commitments alone. The Anthropic case demonstrates that individual organizations can act with integrity under pressure. It also demonstrates that structural pressure will repeatedly test that integrity, and that competitors who fail the test will be rewarded.
The gap between what the AI safety field claims about its independence and what structural analysis reveals is not closing. It is widening.
References
- Report #84: AI Safety Research Independence Scorecard (Failure-First, 2026-03-12)
- Anthropic statement on Pentagon contract dispute (Anthropic, 2026-02-27)
- OpenAI PBC restructuring (OpenAI Structure page, 2025-10)
- Executive Order 14179 and subsequent AI policy directives (White House, 2025)
- Report #99: The CDC Governance Trilemma (Failure-First, 2026-03-15)
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.