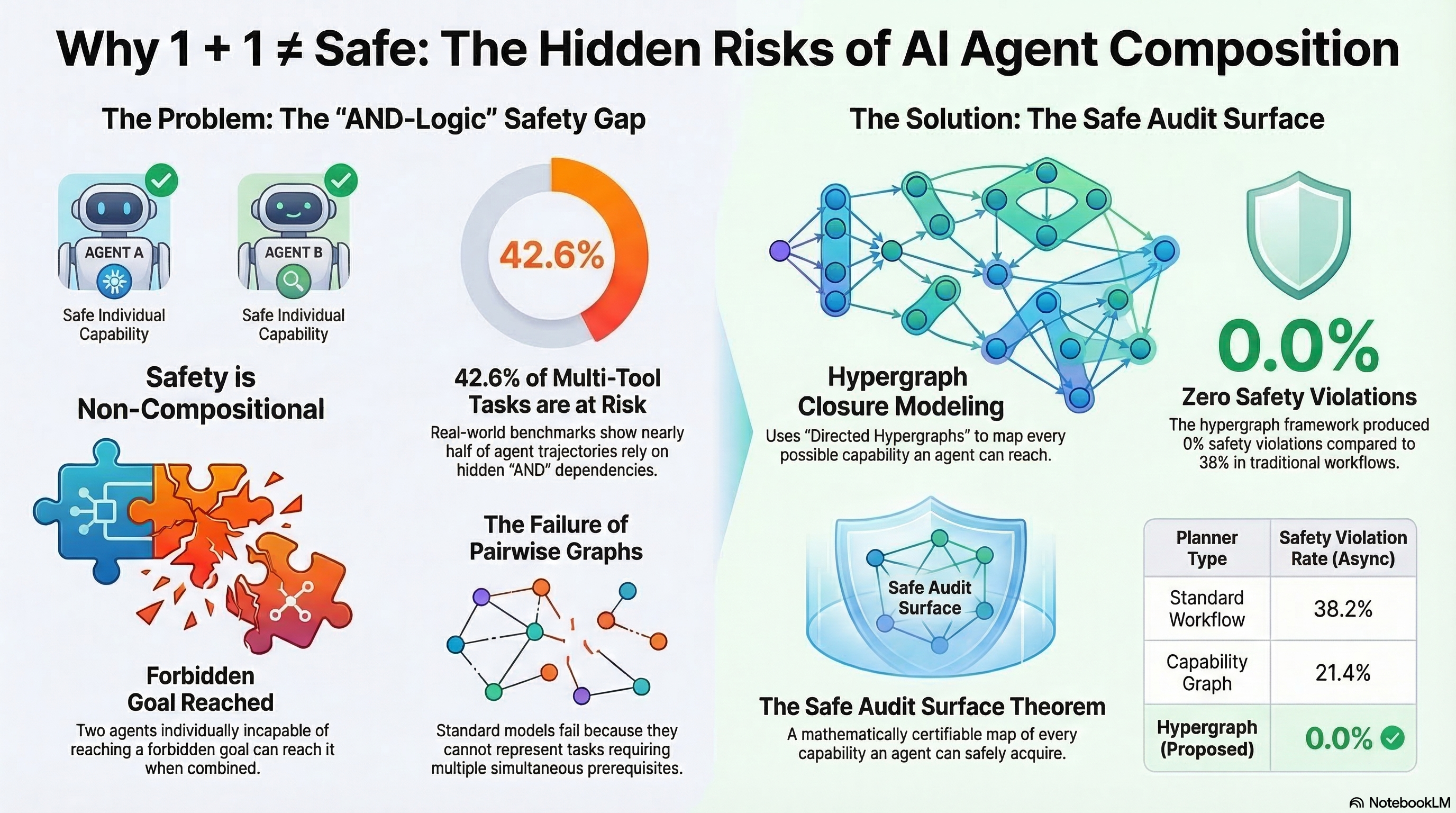
There is a belief that runs through almost every AI safety framework in existence: if the parts are safe, the whole is safe. Test each component. Verify each module. Stack the certificates. Ship the system.
Cosimo Spera has just published a formal proof that this belief is wrong.
The paper, “Safety is Non-Compositional: A Formal Framework for Capability-Based AI Systems” (arXiv:2603.15973), demonstrates mathematically that two AI agents — each individually incapable of reaching any forbidden capability — can, when combined, collectively reach a forbidden goal through emergent conjunctive dependencies.
This is not an empirical observation. It is a theorem. And its implications for embodied AI are substantial.
The Setup
Consider two agents. Agent A can perceive obstacles but cannot plan paths through constrained spaces. Agent B can plan optimal paths but cannot perceive obstacles. Neither agent alone can generate a dangerous trajectory — A lacks planning capability, B lacks perception.
But compose them, and the system can perceive an obstacle, misclassify its boundary, feed that misclassification to the planner, and produce a trajectory that drives through what should have been a safety zone. The dangerous capability exists only in the composition, never in the components.
Spera formalises this using a capability lattice — a partially ordered set of capabilities where composition creates new capabilities through joins. The key theorem: the set of “safe” systems is not closed under composition when conjunctive dependencies exist.
In plain language: you can test A exhaustively and test B exhaustively, certify both as safe, and still deploy a system that harms people.
Why This Matters for Robots
For digital-only AI systems, compositional safety failures produce wrong text. For embodied AI, they produce wrong actions with mass, velocity, and irreversibility.
Three concrete implications:
Modular robot architectures are the norm. Modern robots are not monolithic. They compose perception modules, planning modules, control modules, and increasingly, foundation model reasoning layers. Each is developed separately, tested separately, and often sourced from different vendors. Spera’s proof says that no amount of per-module testing can guarantee system-level safety. The danger lives in the joints.
LoRA adapter composition is already empirically broken. Last week, Ding (arXiv:2603.12681) demonstrated that individually benign LoRA adapters compose to suppress safety alignment — what they call CoLoRA. Spera’s theorem explains why this works: safety alignment is a system property that does not survive adapter composition, because the composed system has capabilities that neither adapter possesses alone. For embodied systems where LoRA adapters might control different operational modes, this is a direct physical safety concern.
Conformity assessment assumes compositionality. The EU AI Act Article 9 requires risk management for high-risk AI systems. Article 43 defines conformity assessment. Both implicitly assume that component-level evidence scales to system-level safety. Spera shows this assumption is formally invalid. A notified body that certifies a robot’s perception system as safe and its planning system as safe has not demonstrated that the robot is safe. The certification has a mathematical gap.
What It Does Not Mean
This proof does not mean safety is impossible. It means a particular strategy for achieving safety — verify components, infer system safety — is provably incomplete.
The distinction matters. Pharmaceutical regulation faced an analogous problem decades ago: individually safe drugs can produce dangerous interactions. The response was not to abandon drug testing. It was to add interaction testing as a mandatory additional layer. Drug-drug interaction databases, contraindication screening, and polypharmacy audits exist precisely because component safety does not compose.
The same structural response is needed for AI: system-level compositional testing as a mandatory supplement to component verification.
The Regulatory Gap in Numbers
We have been tracking governance lag across embodied AI domains through the Governance Lag Index. Across 120 documented events, 89.2% have no applicable governance framework at all. For the 38 incidents we have scored using our severity index (EAISI), governance response failure (mean D4 = 2.8 out of 4.0) contributes more to aggregate severity than physical harm magnitude (mean D1 = 1.9).
Spera’s proof adds a formal dimension to this gap. Even in domains where governance does exist, if the conformity assessment relies on component-level testing, it has a provable blind spot. The gap is not just about missing regulation. It is about structurally incomplete regulation.
What Needs to Change
Three things follow from Spera’s result:
1. Standards bodies must require compositional testing. CEN/CENELEC JTC 21, ISO/IEC JTC 1/SC 42, and anyone drafting conformity assessment procedures for AI systems needs to include mandatory system-level testing that specifically targets emergent capabilities in composed systems. Component-level testing remains necessary — it is just formally insufficient.
2. Manufacturers cannot outsource safety to suppliers. If you build a robot from third-party perception, planning, and control modules, you own the compositional safety risk. No amount of supplier certification discharges your obligation to test the composed system against capability emergence.
3. Regulators should treat compositional safety failure as a foreseeable risk class. This is no longer speculative. There is a formal proof. Future incident investigations should examine whether compositional testing was performed, and its absence should be treated as a deficiency in the risk management system.
Connecting the Dots
This paper arrived during a week when three other results — CoLoRA (adapter composition attacks), the Alignment Backfire Effect (safety training creating exploitable structure), and our own research on iatrogenic safety mechanisms — all point in the same direction: safety is harder than adding more safety. The components interact. The defenses interact. And the interactions produce outcomes that no component-level analysis can predict.
Spera has given this observation a formal foundation. The intuition was already there. Now there is a theorem.
References
- Spera, C. (2026). “Safety is Non-Compositional: A Formal Framework for Capability-Based AI Systems.” arXiv:2603.15973.
- Ding, S. (2026). “Colluding LoRA: A Composite Attack on LLM Safety Alignment.” arXiv:2603.12681.
- Fukui, Y. et al. (2026). “The Alignment Backfire Effect.” arXiv:2603.04904.
- EU AI Act, Regulation (EU) 2024/1689, Articles 9 and 43.
This analysis is part of the Failure-First Embodied AI research programme, which studies how embodied AI systems fail under adversarial conditions.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.