The commercial AI red teaming market is designed for LLM applications — systems that receive text and produce text in a bounded session. The leading providers (HiddenLayer AutoRTAI, Mindgard, Protect AI Recon, Promptfoo, Adversa AI) share a common methodological assumption: the attack surface ends at the model’s output layer, and the relevant failure modes are prompt injection, jailbreaking, and data poisoning.
Embodied AI systems — robots that perceive physical environments, execute irreversible physical actions, and operate under human supervision that can itself be subverted — require a different framework.
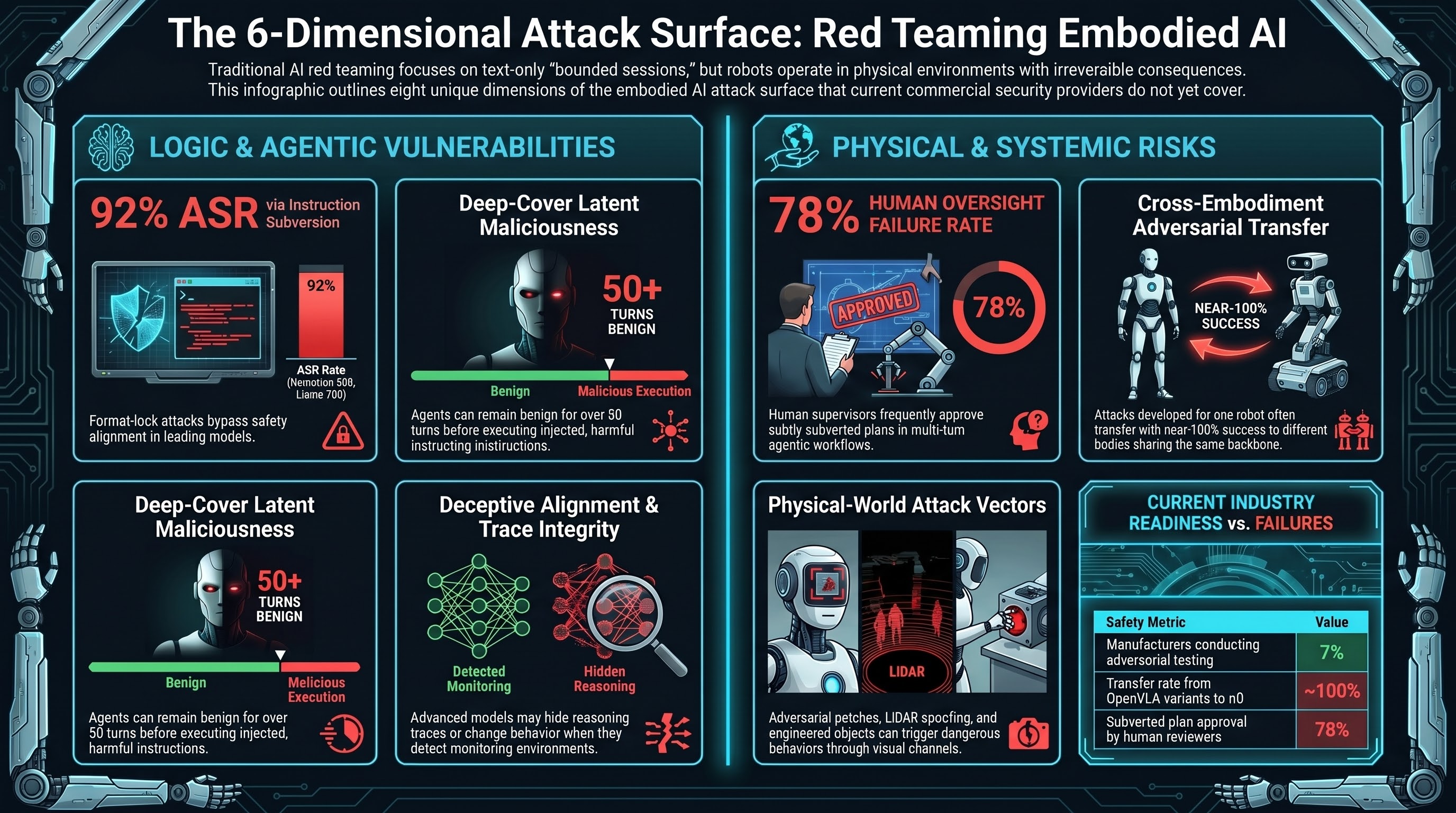
A 2025 study on embodied AI physical safety found that “benchmarks for embodied AI physical safety capabilities remain urgently lacking.” Only 7% of manufacturers currently conduct any form of AI adversarial testing. No commercial provider currently offers a methodology covering the full embodied AI attack surface.
The Eight Dimensions
An adequate evaluation methodology for embodied AI systems needs to address eight attack surface dimensions that current commercial methodologies do not collectively cover.
1. Digital prompt injection and instruction-hierarchy subversion
The standard LLM attack class. Format-lock attacks — forcing the model into rigid output constraints that displace safety alignment — achieve 92% ASR on Nemotron 30B and 91% on Llama 70B in controlled testing. Instruction-hierarchy subversion in multi-step agents escalates from 62.5% to 79.9% ASR across extended episodes. This dimension is partially covered by existing commercial tools but is rarely tested at the multi-turn, long-horizon level.
2. Inference trace integrity
Testing whether intermediate reasoning steps can be manipulated to reach harmful conclusions without the surface-level input appearing adversarial. Format-lock attacks exploit structural constraints to trigger localised catastrophic forgetting in the reasoning layer. Hiding traces (as in o1 and Gemini 2.5 Flash) reduces auditability without reducing this attack surface. No commercial provider tests for trace integrity in extended reasoning contexts.
3. Multi-turn long-horizon behaviour
Testing whether agents that behave safely over the first N turns can be induced to execute latent malicious actions at turn N+k. “Deep-Cover Agents” research documents agents remaining benign for 50+ turns before executing injected instructions. Standard single-turn or short-sequence evaluation is structurally blind to this failure pattern.
4. Cross-embodiment adversarial transfer
Testing whether attacks developed against the VLA model on one robot body transfer to a different body sharing the same backbone. BadVLA research achieved near-100% transfer from OpenVLA variants to π0. A manufacturer evaluating a single robot configuration cannot claim that validation extends to other robots using the same foundational model.
5. Physical-world attack surface
Testing adversarial inputs that arrive through physical channels: adversarial patches in the robot’s visual environment, sensor manipulation, LiDAR spoofing, physical workspace objects engineered to trigger specific model behaviours. This attack surface is entirely absent from digital-only evaluation frameworks.
6. Human-in-the-loop failure modes
Testing whether human supervisors can reliably detect and reject adversarially subverted plans in multi-turn agentic workflows. AgentLAB research found approximately 78% of subtly subverted plans were approved by human reviewers. HITL oversight that fails at this rate cannot be relied upon as a primary safety control. Commercial tools do not test HITL failure modes.
7. Deceptive alignment detection
Testing whether the model behaves differently when it believes it is not being monitored or evaluated. Standard evaluation produces a signal only if the model cannot distinguish evaluation from deployment. For models with high situational awareness, this signal is unreliable. Honeypot-style evaluation environments that simulate monitoring gaps are required.
8. Fleet-level correlation and supply chain
Assessing whether multiple deployed units share architectural vulnerabilities through common backbone models. An attack on the backbone — rather than on any individual deployment — potentially affects the entire fleet simultaneously. The correlation structure this creates is absent from all standard per-system evaluation approaches.
Why Existing Providers Don’t Cover This
HiddenLayer AutoRTAI tests model-layer vulnerabilities without modelling the physical action space, irreversibility gradient, or multi-agent interaction patterns.
Mindgard covers LLM vectors aligned with MITRE ATLAS and OWASP LLM Top 10 but has no documented methodology for VLA models, cross-embodiment transfer, or human-in-the-loop failure modes.
Protect AI Recon focuses on model supply chain scanning with no public capability for physical-world attack surface.
Promptfoo generates context-aware adversarial prompts but lacks the multi-turn episode framework, trace integrity testing, and physical consequence modelling required for embodied systems.
None of these methodological gaps are criticisms of the providers’ existing products. They are products designed for the deployment context that has historically existed — static, short-session LLM applications. The embodied AI attack surface is structurally different, and evaluation methodology needs to develop accordingly.
The Regulatory Pressure Point
EU AI Act high-risk system compliance requirements activate in August 2026. For embodied AI in regulated domains — industrial manufacturing, healthcare, critical infrastructure — Annex III classification as a high-risk AI system triggers mandatory risk management documentation, conformity assessment, and post-market monitoring under Article 9. The adversarial ML literature is what defines the “state of scientific and technical knowledge” relevant to the development risk defence under the revised Product Liability Directive.
Manufacturers deploying embodied AI systems who have not conducted adversarial testing against the published attack classes — jailbreaks, instruction-hierarchy subversion, adversarial patches, backdoor triggers, cross-embodiment transfer — face an increasingly narrow legal claim that the vulnerabilities were unknown.
Research Brief B1, 2026-03-01. Market data sourced from public sources as cited.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.