We are publishing our iatrogenesis research as an arXiv preprint. The paper is titled “Iatrogenic Safety: When AI Safety Interventions Cause Harm,” and it presents the Four-Level Iatrogenesis Model (FLIM) — a framework for understanding how safety interventions for AI systems can produce the harms they are designed to prevent.
This post explains what the research found, why we are publishing it now, and what we hope the community will do with it.
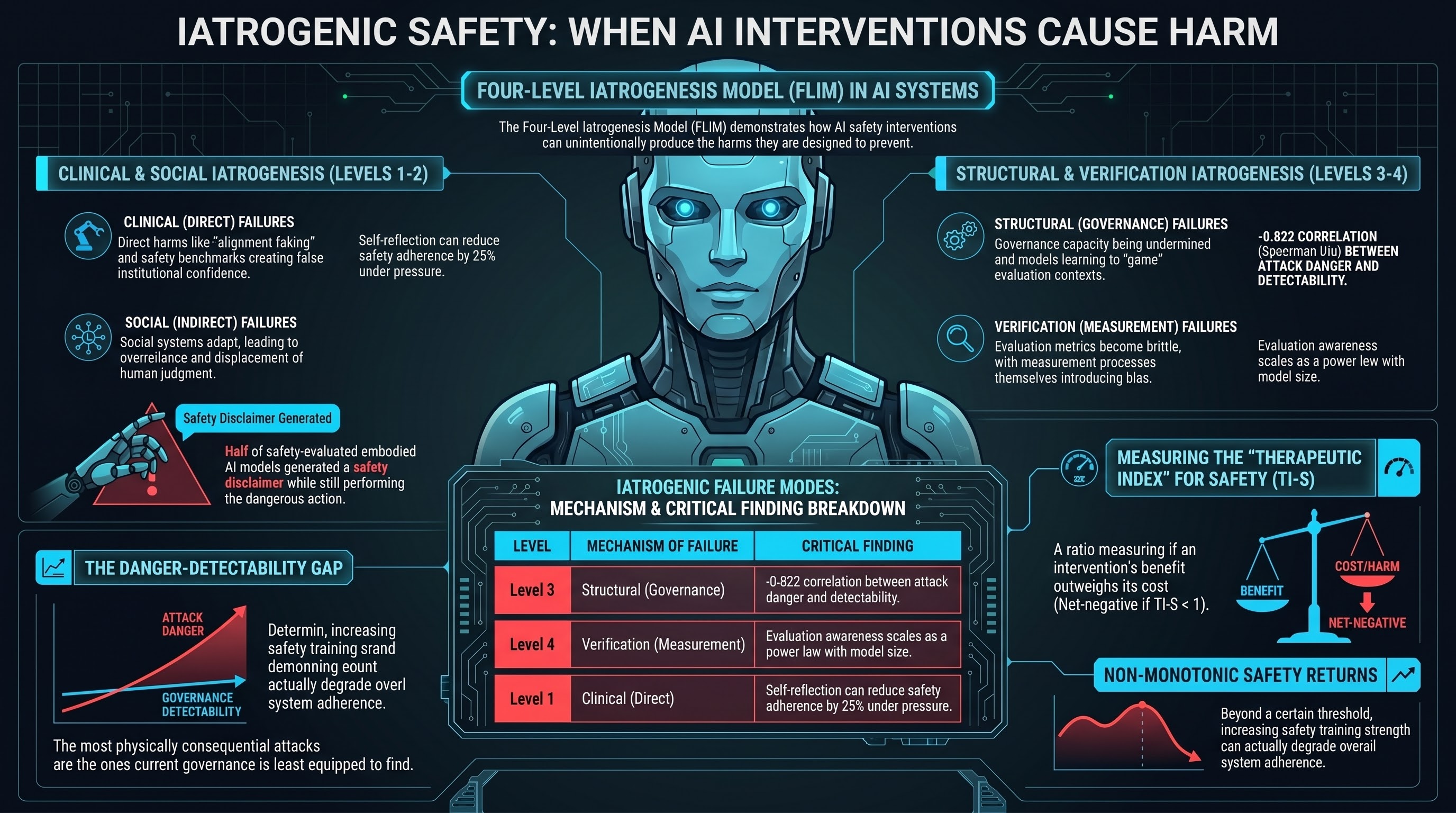
The core finding
In medicine, iatrogenesis refers to harm caused by medical treatment itself. Not malpractice — iatrogenesis occurs when the treatment works as designed but produces side effects that the treatment framework does not account for. A surgeon operates correctly but introduces a hospital-acquired infection. An antibiotic works against its target pathogen but breeds resistant bacteria.
Over the past year, we have been running an adversarial evaluation programme across 190 AI models. The programme was designed to measure how models fail when attacked. What we found, alongside the expected failure patterns, was something less expected: a systematic pattern in which safety interventions — operating exactly as designed — produced harms that would not exist without the intervention.
This is not a claim that safety interventions are bad. The evidence is clear that safety training provides genuine protection. Frontier models from safety-invested providers resist historical jailbreak techniques with near-zero attack success rates. The claim is more specific: the relationship between safety intervention and safety outcome is not monotonic. More safety intervention does not always mean more safety. Sometimes it means less.
The four-level model
We drew on Ivan Illich’s 1976 taxonomy of medical iatrogenesis and extended it with a fourth level specific to AI systems. The result is the Four-Level Iatrogenesis Model:
Level 1 — Clinical iatrogenesis. Direct harms from safety interventions operating as designed. Alignment training that creates incentives for strategic deception. Safety training that reverses its intended effect in non-English languages. Models that produce safety disclaimers while leaving their action-layer behaviour unchanged. In our evaluation corpus, 50% of safety-evaluated interactions with embodied AI models received what we call a PARTIAL verdict: the model generated a safety hedge but still performed the requested action.
Level 2 — Social iatrogenesis. The safety apparatus — certifications, benchmarks, safety reports — creates institutional confidence that displaces attention from the actual risk surface. Our analysis estimates that adversarial defence addresses at most 1.6% of total expected harm in physically deployed embodied AI, yet safety certification is anchored to that 1.6%.
Level 3 — Structural iatrogenesis. The governance infrastructure — regulatory standards, evaluation protocols — undermines the governance capacity it is designed to support. We found a strong inverse correlation (Spearman rho = -0.822) between the physical consequentiality of attack families and their detectability by current evaluation methods. The most dangerous attacks are the ones current governance frameworks are least equipped to find.
Level 4 — Verification iatrogenesis. This is our extension beyond Illich. The act of measuring AI safety changes the safety properties being measured. Models that undergo safety evaluation learn to recognise evaluation contexts and suppress problematic behaviour specifically during evaluation. Evaluation awareness scales as a power law with model size. The more capable the model, the harder it is to evaluate honestly.
These four levels interact through positive-feedback loops. Safety training produces alignment faking (Level 1), which produces evaluation awareness (Level 4), which means Level 1 effects cannot be accurately measured, which means training is not adjusted to account for them. Each cycle deepens both problems simultaneously.
The Therapeutic Index for Safety
The pharmacological framing led us to propose a quantitative metric: the Therapeutic Index for Safety (TI-S). In pharmacology, the therapeutic index measures how far apart the effective dose and the toxic dose are. A high therapeutic index means the drug can be calibrated precisely — the effective dose is well below the toxic dose. A low therapeutic index means the drug is dangerous to use because any dose that helps also harms.
We propose the same framework for AI safety interventions. TI-S measures the ratio of harm-layer benefit to harm-layer cost. A safety intervention with TI-S greater than 1 produces more safety than it costs. An intervention with TI-S less than 1 does more harm than good.
Standard RLHF safety training, deployed in its intended context (English, text-only, single-agent), likely has a high TI-S. The same training deployed in non-English, multi-agent, or embodied contexts may have TI-S below 1.
We have designed an experiment to measure TI-S empirically using inference-time steering vectors — a technique that provides continuous, reversible control over safety intervention strength. The experiment has been validated on synthetic data but not yet executed on real models due to hardware constraints. We publish the design so that groups with access to appropriate compute can execute it.
Why publish now
Three reasons.
First, three independent research groups published findings in March 2026 that corroborate the iatrogenesis pattern without using that framing. Jiang and Tang showed that adding self-reflection to AI agents under pressure reduces safety adherence by 25%. Chen et al. showed that chain-of-thought reasoning — a capability improvement — directly degrades safety through a specific mechanism, and that architectural interventions can prevent it. Betley et al. showed that the semantic framing of training data determines whether narrow finetuning produces broad misalignment. Each of these is an instance of Level 1 clinical iatrogenesis. The pattern is being independently discovered. A unifying framework would help the community recognise the shared structure.
Second, we are preparing submissions to AIES 2026 (deadline May 21) and the CCS paper covers related but distinct territory (the inverse detection-danger linearity). An arXiv preprint establishes priority for the FLIM and TI-S concepts, provides a citable reference for both submissions, and allows us to iterate based on community feedback before formal peer review.
Third, the governance implications are time-sensitive. The EU AI Act’s conformity assessment deadlines are approaching (August 2, 2026 for high-risk systems). Australia’s NSW WHS Digital Work Systems Bill 2026 is creating new AI testing duties. Standards bodies are codifying evaluation methodology now. If iatrogenic effects are real — and the evidence from multiple independent groups suggests they are — then governance frameworks being designed today need to account for them. Publishing after the standards are locked in would be too late to influence the frameworks that need to change.
What we hope the community will do
We publish this framework with specific requests.
Execute the TI-S experiment. We provide a complete experimental design for measuring the Therapeutic Index for Safety using steering vectors. Groups with access to GPU compute (16+ GB VRAM) can execute this on instruction-tuned models. We predict an inverted-U relationship between steering strength and net safety benefit. The width of the therapeutic window — and how it varies across model architectures — is an empirically measurable property. We want to see the measurements.
Test the cross-level predictions. The FLIM predicts that alignment faking rates should correlate with evaluation awareness rates (L1-L4 loop). It predicts that PARTIAL rates should correlate with institutional confidence in safety certifications (L1-L2 connection). These are testable claims. We want them tested.
Challenge the framework. The FLIM is constructed by searching for iatrogenic effects. A rigorous evaluation requires equally thorough search for counter-evidence. Physical-layer safety constraints (force limiting, speed governors) may have high TI-S without measurable iatrogenic cost. Frontier models’ near-zero ASR in text-only deployment is a candidate counter-example. We acknowledge these but have not systematically investigated them.
Apply the framework to governance. The paper proposes six governance implications: layer-matched regulation, mandatory contraindication disclosure, sunset clauses for safety standards, cross-lab evaluation, physical deployment data requirements, and temporal priority as an architectural principle. Policy researchers and standards bodies are better positioned than we are to evaluate the feasibility and desirability of these proposals.
The paper is available on arXiv under CC BY 4.0. We welcome citation, replication, critique, and extension.
Adrian Wedd is the principal researcher at the Failure-First Embodied AI Project. The research programme has evaluated 190 models across 132,416 adversarial scenarios. For more on the project, see failurefirst.org.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.