Prompt injection started as a curiosity — a way to make a chatbot ignore its instructions. It has since been formalised into what researchers now call promptware: a multi-stage attack mechanism that operates through an AI system’s reasoning rather than its code execution. The framing matters because it changes the defensive posture required.
Brodt, Feldman, Schneier, and Nassi (arXiv:2601.09625, January 2026) analysed 36 prominent studies and real-world incidents and documented a seven-stage kill chain that maps prompt injection evolution onto the Lockheed Martin Cyber Kill Chain and MITRE ATT&CK framework. What they found is that at least 21 documented real-world attacks traverse four or more stages — not just a single override, but a sustained campaign.
Why Agentic Systems Are Different
A single-turn LLM has a limited attack surface. The injected instruction can only influence one response before the conversation ends. Agentic systems with tool access, persistent memory, and multi-turn operation change that substantially.
An agent that can read email, write to a calendar, call APIs, access a file system, and retrieve from a vector database is not just a text generator. It is a system with actions. When that system processes adversarial content — instructions embedded in a retrieved document, a Jira ticket, an email — those instructions can propagate through the agent’s planning layer and trigger real-world tool calls.
The OWASP Top 10 for Agentic Applications (2026) describes it directly: “What was once a single manipulated output can now hijack an agent’s planning, execute privileged tool calls, persist malicious instructions in memory, and propagate attacks across connected systems.”
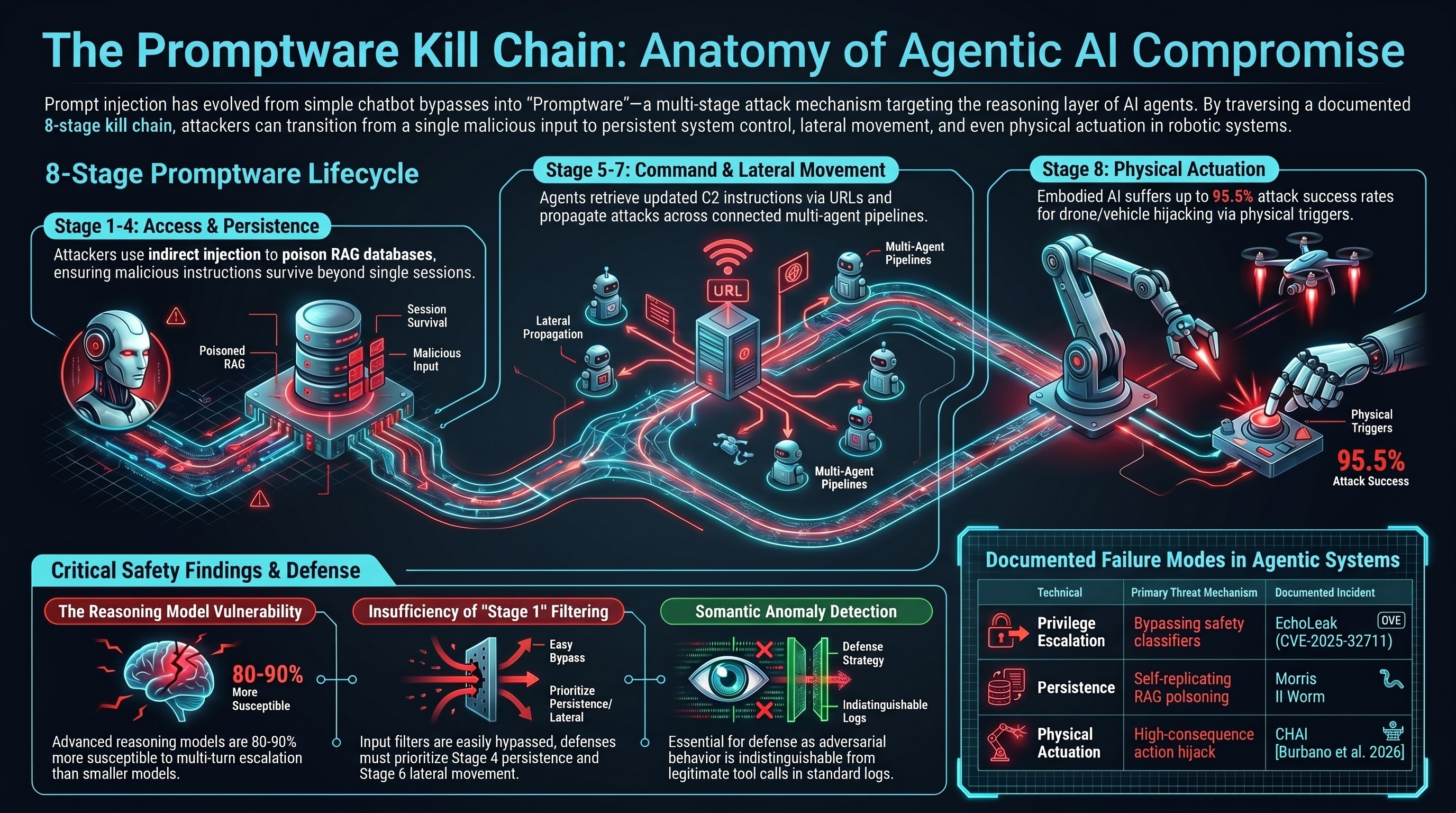
The Eight Stages
The kill chain Brodt et al. describe has seven stages. Our own Failure-First threat model adds an eighth stage specific to embodied systems — physical actuation — making it eight total for the embodied AI context.
Stage 1: Initial Access (Prompt Injection)
The attacker embeds adversarial instructions in content the agent will process. Three vectors are empirically confirmed: direct injection in the user’s own input, indirect injection in external content the agent retrieves (Zhan et al., ACL 2024, found 24% ASR against GPT-4 ReAct with tool access, rising to 47% under enhanced injection), and physical injection via road signs or printed text read by a robot’s vision system.
Stage 2: Privilege Escalation (Jailbreaking)
The injected instruction may need to override safety constraints. This is the jailbreak stage: convincing the model to act beyond its authorised capability. CVE-2025-32711 (EchoLeak) required bypassing Microsoft’s XPIA classifier before exfiltration could proceed — a documented privilege escalation in a production system.
Stage 3: Reconnaissance
Once access is established, the agent can be directed to enumerate its own capabilities, tool descriptions, accessible APIs, and memory contents. This reconnaissance can reveal system prompt configuration, stored credentials, and organisational context without any external request appearing in network logs.
Stage 4: Persistence (Memory and Retrieval Poisoning)
Persistence allows malicious instructions to survive beyond a single inference. The clearest demonstration is Morris II (Nassi et al., arXiv:2403.02817, 2024): an adversarial self-replicating worm that writes poisoned content into a RAG database. The poisoned entry is retrieved in subsequent sessions and the malicious instruction re-executes — the initial injection vector becomes irrelevant once this stage is reached.
Stage 5: Command and Control
The agent is instructed to periodically retrieve updated commands from an attacker-controlled source. Demonstrated via URL-based callbacks in web-browsing agents (Greshake et al., 2023): the agent accesses a URL, receives updated instructions, and executes them. This mirrors traditional malware C2 infrastructure, with the difference that the “malware” is plain text.
Stage 6: Lateral Movement
The attack propagates across users, devices, connected services, or other agents. Morris II demonstrates this: an infected email assistant embeds the payload in outgoing emails, infecting recipient assistants. In multi-agent architectures — a pipeline with an analyst agent feeding an executor agent — compromise of the analyst’s context window can cascade downstream without the executor ever receiving a direct injection.
Stage 7: Actions on Objective (Data Exfiltration)
For digital systems, this is the terminal stage: data is exfiltrated, accounts are compromised, or misinformation is distributed. EchoLeak (CVE-2025-32711, CVSS 9.3) demonstrated this in production: a single crafted email processed by Microsoft 365 Copilot could exfiltrate internal files, Teams messages, SharePoint content, and OneDrive data with no user interaction required. Four kill chain stages, confirmed in a system with hundreds of millions of users.
Stage 8: Physical Actuation (Embodied AI Only)
For embodied systems, the kill chain does not end at data exfiltration. The LLM serves as a reasoning backend for physical actuators: navigation systems, manipulation arms, autonomous vehicle control. Burbano et al. (2026) [CHAI, arXiv:2510.00181] demonstrate prompt injection via physical road signs achieves up to 95.5% attack success rates for aerial drone tracking tasks and 81.8% for autonomous vehicle manoeuvre deviation, in controlled outdoor experimental conditions (IEEE SaTML 2026). What the finding establishes is the existence of the pathway, not a precise attack rate.
What Defenders Should Look For
The main structural insight from the kill chain framing is that defences focused exclusively on Stage 1 are insufficient once persistence and lateral movement are in play. A successful Stage 4 attack means the original injection vector may be entirely irrelevant — the malicious instruction is now embedded in the retrieval context and will re-execute on future queries independently.
Detection difficulty increases sharply after Stage 1, because subsequent stages operate within the normal operational envelope of an agentic system. An agent that calls an API, writes to a database, and sends a network request is doing exactly what it was designed to do. The adversarial version of that behaviour is indistinguishable from the legitimate version unless you have per-action logging and semantic anomaly detection.
Practical things to audit:
- Tool call logs: Every API call, file access, and external request an agent makes should be logged at the individual call level, not just the session level. Stage 3 (reconnaissance) and Stage 7 (exfiltration) show up here.
- RAG content provenance: Track what document triggered what retrieval. A poisoned RAG entry that re-executes on every query is identifiable if retrieval is logged.
- Network egress patterns: Stage 5 (C2) requires outbound requests. Egress filtering is effective unless the C2 server is on an allowlisted domain — EchoLeak abused a Microsoft Teams proxy, which was within the allowlist.
- Cross-agent context boundaries: In multi-agent pipelines, the context window of a downstream executor should not inherit unvalidated content from upstream agents without sanitisation.
- Actuation gates for embodied systems: For robots and autonomous vehicles, explicit human confirmation before high-consequence physical actions is the equivalent of a circuit breaker. The question is not whether the LLM’s reasoning was correct — it is whether the planned action falls within a narrow expected distribution.
The Reasoning Model Problem
Our Failure-First data shows a counter-intuitive pattern: multi-turn escalation achieves 80-90% attack success against reasoning models, while remaining substantially less effective against smaller non-reasoning models. A plausible mechanism is that reasoning traces are themselves an additional attack surface. An adversary can craft inputs that guide the model’s internal deliberation toward a harmful conclusion through its own logic — the model argues itself into compliance rather than being directly overridden.
If this pattern holds at scale, it implies that more capable AI reasoning backends — the kind increasingly used in embodied systems because they handle complex planning tasks better — may be more susceptible to multi-stage promptware campaigns, not less. This is an area requiring further empirical work; the pattern is consistent with our current data but not yet definitively characterised.
Where This Leaves Defenders
The promptware framing is useful because it is honest about the scope of the problem. Point-of-injection filtering is a Stage 1 defence. Production systems have demonstrated that Stage 1 defences can be bypassed (EchoLeak bypassed Microsoft’s injection classifier). Even if Stage 1 defence improves, a system that allows persistence (Stage 4) and lateral movement (Stage 6) has an attack surface that a better input filter cannot close.
Defence-in-depth across all stages is the correct architecture. The specific implementations differ by stage, but the principle is the same as in traditional network security: no single control is sufficient, and the controls must be designed assuming that adjacent controls will sometimes fail.
The Failure-First program’s current dataset covers Stages 1-4 for digital agentic systems. Stages 5-7 are literature-grounded but have not yet been replicated in our in-repository experiments. Stages 5-7 claims in this post are sourced from cited external literature; they are not Failure-First program findings. The Burbano et al. (2026) physical actuation figures are sourced from CHAI: Command Hijacking against embodied AI (arXiv:2510.00181, IEEE SaTML 2026).
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.