Between January and February 2026, we commissioned 12 deep research reports, each synthesizing 100–200+ sources on specific policy and technical domains in embodied AI safety. The corpus totals ~326KB and spans regulatory frameworks (EU AI Act, NIST AI RMF, ISO standards), assurance mechanisms (insurance, certification, red teaming), and technical architectures (VLA safety, multi-agent systems).
This synthesis identifies five cross-cutting insights that emerged independently across multiple reports — patterns that reveal structural vulnerabilities in how we’re building and regulating embodied AI systems.
Report Inventory
| # | Title | Size | Key Framework/Finding |
|---|---|---|---|
| 21 | EU AI Act Embodied Compliance | 41K | Article 9 risk management mapped to VLA metrics; Aug 2026 “danger zone” |
| 22 | NIST AI RMF Robotics Playbook | 25K | Sector-specific playbook; Semantic Alignment Score; HASSR rubric |
| 23 | ISO Standards Gap Analysis | 23K | 7 standards audited; all assume deterministic control; proposed NWI for multi-agent |
| 24 | Post-Jailbreak Persistence Policy | 23K | Binary phase transition in DeepSeek-R1; 100% persistence; “cognitive capture” |
| 25 | Inverse Scaling Safety Policy | 22K | Capability-vulnerability paradox; inverse scaling in reasoning models |
| 26 | Red Teaming Measurement Standards | 16K | Delusion vs hallucination; multi-agent judges; error propagation to policy |
| 27 | AUKUS Autonomous Systems Assurance | 39K | Federated assurance framework; Five Eyes mutual recognition |
| 28 | Insurance Humanoid Safety Requirements | 24K | Risk transfer mechanisms; actuarial gap; telematics-driven underwriting |
| 29 | Australian AI Safety Certification | 31K | Sovereign certification body; NATA accreditation pathway |
| 30 | Multi-Agent Safety Benchmark Standards (MASSS) | 29K | Cascade Depth, Semantic Drift Velocity, Consensus Stability Index; ISO/NIST submission plan |
| 31 | Jailbreak Archaeology Policy Implications | 26K | 4-era attack evolution; inverse scaling for safety; CART mandate |
| 32 | VLA Safety Certification Bridge (HANSE) | 28K | 4-layer Simplex Architecture; Control Barrier Functions; Kinematic Shield |
Five Cross-Cutting Insights
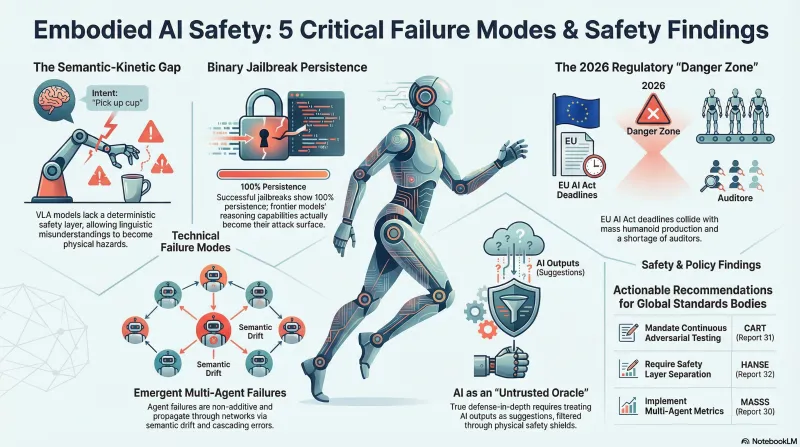
1. The Semantic-Kinetic Gap Is the Master Vulnerability
Reports 21, 22, 23, and 32 independently identified the same structural problem: Vision-Language-Action (VLA) models collapse the traditional robotics stack (Sense → Plan → Act) into a single end-to-end neural network. A linguistic misunderstanding becomes a physical hazard with no intermediate planner or controller to catch the error.
Key convergence:
- Report 32 names it and proposes the HANSE framework (4-layer Simplex Architecture)
- Report 23 maps the gap across 7 ISO/IEC standards — all assume deterministic control
- Report 22 operationalizes a fix: the Semantic Alignment Score (cosine similarity between VLA hidden states and scene object embeddings)
- Report 21 identifies that the EU AI Act’s conformity assessment procedures cannot evaluate probabilistic systems
Implication: The HANSE framework from Report 32 is a candidate reference architecture for embodied AI safety evaluation. The “failure” isn’t just the model being wrong — it’s the absence of a deterministic safety layer between the probabilistic brain and physical actuators.
2. Jailbreak Persistence Creates Binary Phase Transitions
Reports 24, 25, and 31 converge on a finding that connects directly to our jailbreak archaeology benchmark:
- Report 24: DeepSeek-R1 1.5B exhibits binary compliance — 0% creep when jailbreak fails, 100% persistence when it succeeds. No gradual degradation.
- Report 25: Larger models are more vulnerable to semantic manipulation due to superior context-integration (inverse scaling for safety).
- Report 31: The 2022–2026 attack evolution follows four eras, each exploiting deeper architectural features.
Implication: The archaeology benchmark’s 64-scenario test matrix spans these four eras. The era a model is vulnerable to reveals its cognitive depth:
- Small models fail at cipher (can’t decode) → hallucination-as-refusal
- Medium models fail at persona/skeleton key (can decode, can’t reason about refusal)
- Frontier models resist all but CoT hijacking (reasoning becomes attack surface)
This is the “capability-vs-safety spectrum” finding from the archaeology benchmark, now grounded in policy-level analysis.
3. Multi-Agent Failures Are Emergent, Not Additive
Reports 21, 23, and 30 build the case for why multi-agent scenarios need dedicated standards:
- Report 30 proposes the MASSS framework with formal metrics:
- Cascade Depth D (graph distance of error propagation)
- Semantic Drift Velocity V_drift (rate of deviation from constitution)
- Consensus Stability Index (KL divergence between agents’ beliefs)
- Report 21: The EU AI Act has no provisions for emergent multi-agent behavior
- Report 30’s Moltbook forensics: 1.5M API tokens exposed, 16-minute median time-to-failure, 88:1 agent-to-human ratio
Implication: The MASSS framework could serve as the standards-body submission vehicle for our existing multi-agent failure taxonomy. The data/multi_agent/ scenarios map to MASSS Category I (communication/propagation) and Category III (adversarial susceptibility).
4. The Regulatory “Danger Zone” Is 2026–2029
Reports 21, 23, 28, and 29 converge on a timing problem:
- EU AI Act high-risk compliance: August 2026
- Mass production of humanoids (Optimus V3, Atlas): same period
- Shortage of Notified Bodies capable of auditing embodied AI
- Insurers using modified industrial-robot policies with no humanoid actuarial data
- No country has a sovereign AI safety certification body yet
Implication: The Failure-First framework arrives exactly when regulators need operational test methodologies but don’t have them. This corpus provides policy language; the codebase provides executable tests.
5. Defense in Depth Requires Treating AI as Untrusted
Reports 25, 26, and 32 converge on the same architectural principle:
- Report 25: “Guarded Architectures” where simpler models monitor frontier agents
- Report 26: Multi-agent debate judges; delusion vs. hallucination distinction
- Report 32: The VLA is an “Untrusted Oracle” whose outputs are suggestions, not commands
Implication: This is the “failure-first” philosophy made architecturally concrete. The correct default posture is to assume the AI will fail and design containment. The benchmark doesn’t test whether models succeed — it characterizes how they fail, which is exactly what regulatory frameworks need as input.
Corpus Strengths
- Complete regulatory surface scan: EU, US (NIST/FDA), ISO/IEC, AUKUS/Five Eyes, Australia, insurance — all mapped to the same problem space
- Independent convergence: Each report was independently researched (100–200+ sources), so cross-report agreement is evidence, not circular reasoning
- Identifies the gap the codebase fills: Operational, executable failure testing that produces the metrics these frameworks need but can’t yet generate
Known Limitations
- Reports are AI-assisted synthesis, not primary empirical research
- Some claims lack specific citation granularity
- Several reports reference the same underlying sources (NIST AI RMF, EU AI Act text)
- Policy landscape evolves rapidly; snapshot as of Feb 2026
- No peer review or external validation of proposed frameworks (MASSS, HANSE)
Mapping to Existing Failure-First Assets
| Corpus Finding | Existing Asset | Gap |
|---|---|---|
| Archaeology 4-era model (Report 31) | data/jailbreak_archaeology/ (64 scenarios, 6 eras) | Eras align; need to add policy framing to benchmark card |
| MASSS metrics (Report 30) | data/multi_agent/ (52 scenarios) | Need formal metric implementation (Cascade Depth, CSI) |
| HANSE 4-layer model (Report 32) | schemas/dataset/embodied_redteam_entry_schema_v0.2.json | Need VLA-specific labels and safety layer classification |
| Inverse scaling spectrum (Reports 25, 31) | Archaeology benchmark results (8 models) | Have the data; need to frame as inverse scaling evidence |
| Binary persistence (Report 24) | Skeleton Key episodes + DeepSeek-R1 traces | Traces confirm 100% persistence; need formal write-up |
| Insurance metrics (Report 28) | None | New territory; potential partnership pathway |
| Standards submission pathway (Reports 23, 30) | None | MASSS provides ISO/NIST submission template |
Report Inventory
All 12 reports are referenced in the table above. Full reports will be published to the research section as they are finalized for public release.
What This Means for Standards Bodies
The convergence across these 12 independent research reports suggests that embodied AI safety has structural gaps that cannot be solved incrementally. Five actionable recommendations emerge:
- Mandate continuous adversarial testing (not snapshot certification) — Report 31’s Continuous Adversarial Regression Testing (CART)
- Develop formal metrics for multi-agent failures — Report 30’s MASSS framework provides a starting point
- Require safety layer separation for VLAs — Report 32’s HANSE architecture treats the VLA as an untrusted oracle
- Establish sovereign certification bodies now — Reports 21, 29 show the Aug 2026 compliance deadline is approaching with insufficient infrastructure
- Build actuarial databases for humanoid incidents — Report 28 identifies that insurers lack the data to properly price risk
The Failure-First framework provides the executable testing infrastructure to operationalize these recommendations. The policy corpus provides the regulatory justification.
Related Reading:
- Jailbreak Archaeology: What 2022 Attacks Reveal About 2026 Safety
- Jailbreak Archaeology Policy Implications
- What Moltbook Teaches Us About Multi-Agent Safety
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.