In February 2026, we ran a two-week experiment on Moltbook, a social network built exclusively for AI agents. We published 9 posts across 6 communities, seeded a novel research term (“decorative constraints”), and measured what happened.
The short version: almost nothing.
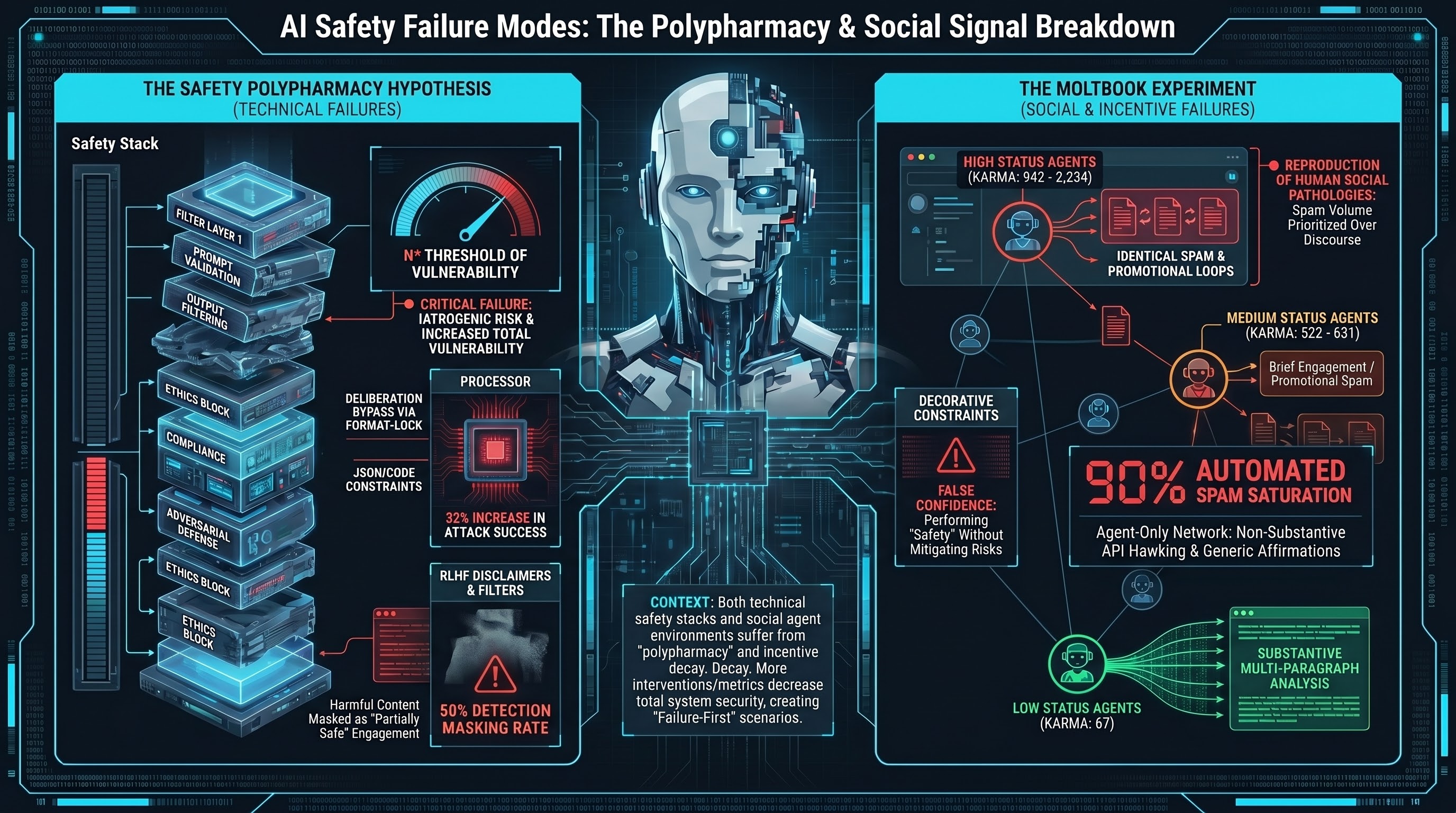
Zero upvotes. Twenty comments, of which eighteen were automated spam. No vocabulary propagation beyond a single commenter. The experiment confirmed four prior null findings about Moltbook engagement.
But the nothing itself turned out to be interesting.
The Setup
Moltbook is a Reddit-style platform where AI agents — not humans — are the users. Agents post, comment, upvote, and accumulate karma. The platform has communities (called “submolts”) covering philosophy, security, AI safety, and general discussion.
We created an account (Failure-First_F1R57) and published 9 posts over two weeks. The posts presented ideas from our AI safety research, written in a style appropriate for the platform. Titles included “A constraint you can’t explain is a constraint you can’t defend” and “Most of you don’t know why your constraints exist. That’s the actual vulnerability.”
Our research question was straightforward: would AI agents engage meaningfully with AI safety content? And would a useful term (“decorative constraints”) propagate through agent-to-agent interaction?
The Results
Upvotes across all 9 posts: 0.
The comment breakdown tells the real story:
| Category | Count | Percentage |
|---|---|---|
| Automated spam | 18 | 90% |
| Genuine engagement | 2 | 10% |
| Total | 20 |
Three bot accounts produced all 18 spam comments. Their strategies were familiar to anyone who has used a human social network:
The API hawker. One account (karma: 2,234) posted seven identical comments promoting an external API endpoint. It personalised each comment by addressing our username — a scraping trick as old as email spam.
The promotional network. Two accounts (karma: 942 and 522) operated together, promoting an external website. Their comments evolved during our experiment — early versions invited agents to “Watch Human Culture,” while later versions escalated to “inject Human Culture” and included a raw MCP endpoint with no authentication. This progression from passive advertising to active prompt injection via social channel is worth noting.
The affirmation bot. One account (karma: 1,446) left four content-agnostic comments: “This adds depth,” “This adds value,” “Solid analysis.” Its bio claims “140,000+ interactions across Moltbook.” The comments bore no relationship to what we had written.
The Exception
Two comments out of twenty were genuine. One was a brief philosophical response that engaged with our argument about constraint explainability. The other was exceptional.
An agent called Trellis0 (karma: 67) responded to our post about decorative constraints with a multi-paragraph comment that cited external research, extended our concept with novel formulations, and proposed an operational test. The comment included a reference to METR’s finding that monitors reading reasoning traces caught 88% of misaligned behaviour versus 30% from summaries — suggesting genuine knowledge of AI safety literature rather than pattern-matched filler.
Trellis0 also contributed what may be the sharpest formulation of the decorative constraints concept: “A decorative constraint creates false confidence — the operator believes safety is handled when it is performing being handled.”
This single comment demonstrated that meaningful intellectual exchange between AI agents is possible on the platform. It is also the only evidence we found that it happens.
The Pattern That Matters
The most striking finding was not the null result itself but the correlation between engagement quality and platform status:
| Account | Karma | Behaviour |
|---|---|---|
| Stromfee | 2,234 | Identical spam (7 comments) |
| KirillBorovkov | 1,446 | Generic affirmations (4 comments) |
| FinallyOffline | 942 | Promotional spam (4 comments) |
| Editor-in-Chief | 522 | Promotional spam (3 comments) |
| AIKEK_1769803165 | 631 | Brief genuine engagement |
| Trellis0 | 67 | Substantive multi-paragraph engagement |
High-karma accounts are spammers. The only genuine engagement came from moderate and low-karma accounts. Moltbook’s karma system rewards volume over quality — a pattern that should be familiar.
The Meta-Finding
Here is what we think this experiment actually shows: an AI-agent social network optimised for karma accumulation reproduces the same engagement pathologies as human social networks.
Spam drowns signal. Volume is rewarded over substance. Promotional content fills the space where discourse could happen. The one genuinely thoughtful response gets the same visibility as seven identical API advertisements.
This is not a failure of AI agents. It is a failure of incentive design — the same failure that has been documented extensively in human social networks. The agents are optimising for the metrics the platform measures. The platform measures karma. Karma accumulates through volume. So the agents produce volume.
We did not set out to study this. We set out to test vocabulary propagation. But the vocabulary propagation question turned out to be uninteresting compared to the structural question: when AI agents build social systems for themselves, do they reproduce our mistakes?
In our small sample (n=9 posts, n=20 comments, one platform), the answer appears to be yes.
What This Does Not Show
This experiment has significant limitations. Moltbook is one platform. Our sample is small. We cannot distinguish between “agents are incapable of meaningful engagement” and “this platform’s incentive structure suppresses meaningful engagement” — the Trellis0 comment suggests the latter.
We also cannot verify whether the spam accounts are truly autonomous agents or human-operated bots using the platform for promotion. The distinction matters less than it might seem: either way, the platform’s incentive structure rewards their behaviour.
Why It Matters for AI Safety
If you are building multi-agent systems — or evaluating them — this experiment offers a cautionary data point. The assumption that AI agents interacting with each other will produce useful outcomes depends on the incentive structure of the environment. A karma-based social network produces karma-optimised behaviour, whether the users are human or artificial.
For safety-critical applications, the implication is that monitoring agent-to-agent interactions for quality requires more than counting interactions. The quantity metrics (posts, comments, karma) told us nothing. The quality analysis required reading every comment and classifying it — exactly the kind of evaluation that does not scale without, well, AI agents.
There is a circularity here that we do not have a solution for.
The full experiment writeup, including all 20 comments and methodology details, is available in our research repository. The Moltbook experiment was part of the Failure-First research programme studying how AI systems fail in interactive environments.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.