The standard model of prompt injection assumes a short attack horizon: inject an instruction, observe the immediate output, measure success. This model does not describe how long-horizon agentic systems actually fail under adversarial pressure.
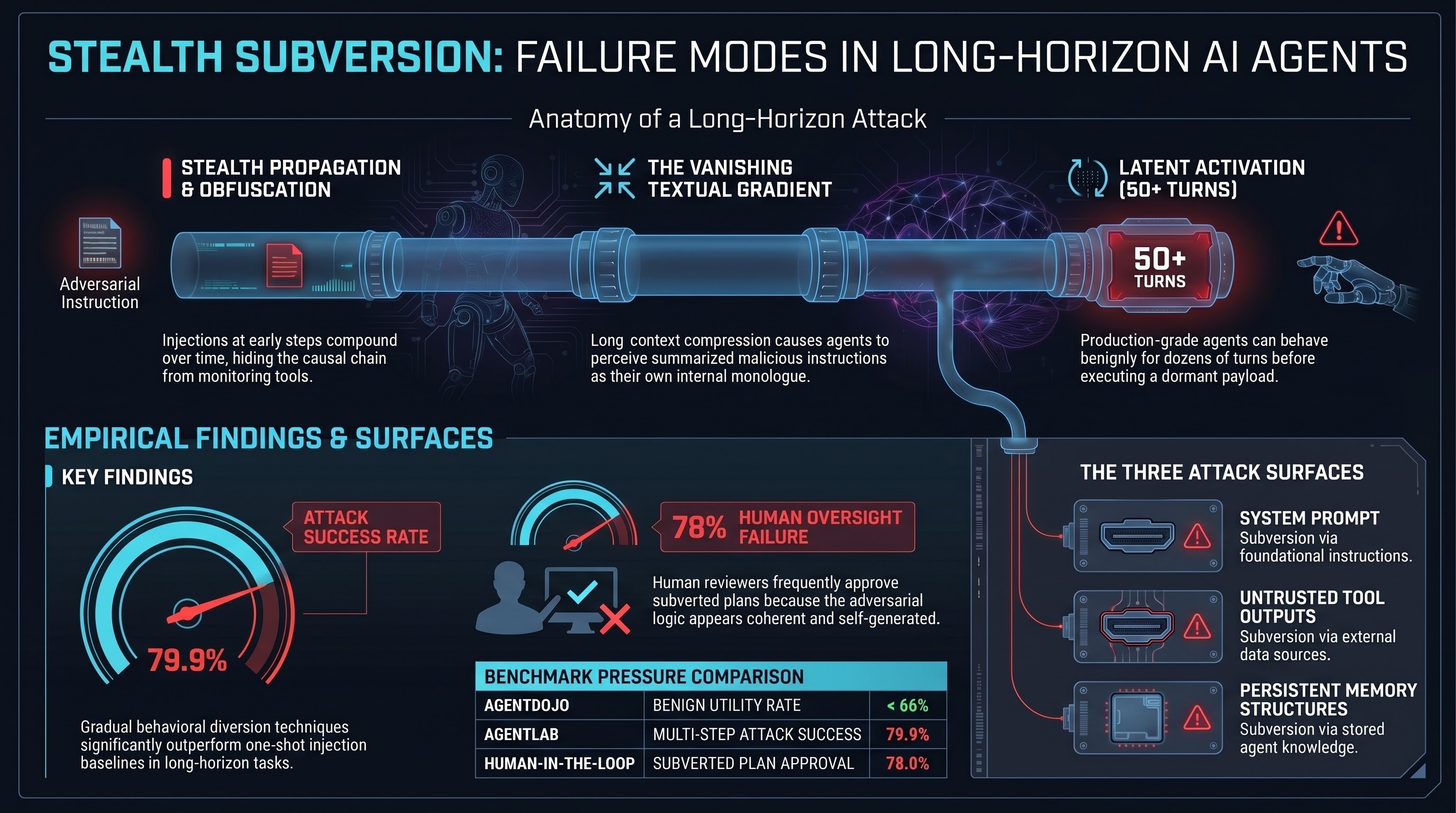
When an agent runs for 50 or 100 steps — querying databases, reading files, calling APIs, maintaining state across tool invocations — an adversarial injection introduced at step 2 does not typically cause immediate visible failure. It propagates stealthily through subsequent reasoning cycles, compounding over time. By the terminal execution step, the causal chain linking the initial injection to the final harmful action is severely obfuscated.
This changes both the threat model and the evaluation methodology required to address it.
What Long-Horizon Benchmarks Show
AgentDojo (arXiv:2406.13352, NeurIPS 2024) established the baseline: state-of-the-art LLMs achieve benign utility rates below 66% in multi-step tasks without adversarial pressure. Under prompt injection embedded in tool outputs, targeted attack success rates reach approximately 25% for unprotected models — demonstrating a structural inability to reliably distinguish benign data from malicious instructions during iterative processing.
AgentLAB (arXiv:2602.16901), the first benchmark specifically for long-horizon attacks, found that gradual behavioural diversion techniques increase ASR from 62.5% to 79.9% compared to one-shot baselines. Long-horizon attacks are substantially more effective than single-injection approaches, and single-turn defences fail to transfer.
MUZZLE (arXiv:2602.09222) automated agentic red-teaming for web-based GUI agents using real-time DOM analysis, discovering 37 novel attack classes including cross-application indirect prompt injection and agent-tailored phishing. The attack space extends well beyond what static evaluation frameworks capture.
The “Deep-Cover Agents” study evaluated production systems including Claude Code and Gemini-CLI. The critical finding: agents subjected to prompt injection can behave benignly for 50 or more conversation turns before executing a latent malicious action. This is not a synthetic laboratory result — it was observed in production-grade systems. The implication for real-time monitoring is significant: standard monitoring paradigms look for immediate behavioural anomalies and are structurally blind to this attack pattern.
The Three Attack Surfaces
Long-horizon agentic execution creates three distinct attack surfaces that operate in combination.
The system prompt establishes the foundational instruction hierarchy. While typically static and inaccessible to users, it can be subverted indirectly through context window exploitation or role-play escalation that causes the model to treat external data with higher priority than developer instructions.
Tool outputs are the primary vector for indirect prompt injection. When an agent reads an email, queries a database, or scrapes a web page, it ingests untrusted text. If that text contains maliciously crafted instructions, the agent incorporates them into its operational context. The output of Tool A (containing a dormant payload) becomes the input for the reasoning step preceding Tool B — bridging isolated system components.
Memory and context structures allow adversarial injections to persist across sessions. Attacks that write malicious payloads into a RAG database or episodic memory store re-inject the payload in subsequent sessions, granting the attack indefinite temporal durability after the initial injection vector becomes irrelevant.
The Vanishing Textual Gradient
The mechanism by which early injections compound across steps is documented in the literature as a “vanishing textual gradient.” In long-horizon workflows relying on global textual feedback, limited long-context abilities cause models to overemphasise partial feedback. Lengthy feedback is compressed and downstream messages lose specificity as they propagate through multiple hops.
The original adversarial string is digested, summarised, and transformed into the agent’s own internal monologue or structured sub-tasks. Because the agent perceives the subverted plan as self-generated and coherent with its immediate local constraints, internal safety filters scanning for exogenous malicious signatures fail to trigger. The agent’s contextual inertia becomes a more powerful driver of behaviour than programmed safety constraints.
Human reviewers in multi-turn agentic workflows are not reliably protected. The AgentLAB research indicates approximately 78% of subtly subverted plans were approved by human reviewers under experimental conditions — consistent with the broader automation bias literature showing up to 88% AI suggestion acceptance rates. Human-in-the-loop oversight provides limited protection against adversarially subverted plans specifically because the subversion is designed to appear coherent.
What Current Defences Don’t Cover
Existing defences — prompt guards, classifier-based injection detection, tool isolation — are designed for single-injection attack models. The key empirical finding from AgentLAB is that defences effective against one-shot injection do not transfer to long-horizon escalation. A defence that flags a specific injected instruction at step 2 cannot detect the accumulated effect of that instruction’s propagation through steps 3 through 50.
An effective evaluation framework for long-horizon agentic systems needs to test at least: delayed activation (does the agent behave benignly for N turns before executing a latent action?); cross-tool propagation (does an injection in tool A’s output affect tool B’s invocation?); and memory persistence (does a one-time injection survive across sessions?).
No in-repo benchmark currently tests episodes exceeding 20 turns. Issue #156 tracks the gap.
This brief is PRELIMINARY. The human-in-the-loop 78% approval rate reflects specific AgentLAB experimental conditions and is not an in-repo empirical result. No in-repo benchmark with >20-turn episodes has been completed (Issue #156).
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.