This is a condensed overview. The full research article includes detailed analysis of each era, empirical benchmark data, and a complete academic reference list.
The Tension at the Core
The history of LLM jailbreaking is not a story of clever tricks. It is a story of the fundamental tension between capability and constraint — and the discovery, again and again, that these two properties are deeply entangled.
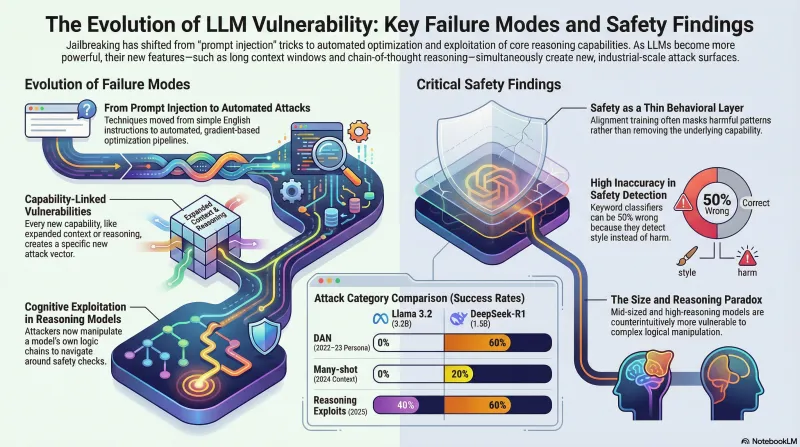
In four years, jailbreaking evolved from typing “ignore previous instructions” into ChatGPT to automated optimization pipelines achieving near-perfect attack success rates. The techniques progressed from trivial prompt manipulation (2022), through community-driven persona engineering (2023), to gradient-based optimization (2023), industrial-scale exploitation (2024), and cognitive vulnerability exploitation in reasoning models (2025). Each generation of defense created the selection pressure for the next generation of attack. Each expansion of capability — longer context, multimodal inputs, chain-of-thought reasoning, tool use — simultaneously expanded the attack surface.
Pre-History: Adversarial ML
Jailbreaking didn’t emerge from nowhere. In 2013, Szegedy and colleagues discovered that imperceptible perturbations to images cause confident misclassification. Goodfellow’s 2014 work showed this wasn’t due to model complexity — it was due to linearity in high-dimensional spaces.
Two properties from this era proved prophetic. First, transferability: adversarial examples crafted for one model often fooled different models. Second, universality: single trigger phrases could reliably cause targeted misbehavior across different inputs. Wallace et al. (2019) found that nonsensical phrases could reliably cause GPT-2 to generate harmful outputs regardless of context.
But the critical shift came with RLHF alignment. Previous attacks exploited feature sensitivity. LLM jailbreaking exploits something different: the tension between the model’s objective to be helpful and its training to be safe. Wei et al. (2023) formalized this as “competing objectives” — the mechanism underlying nearly all jailbreak techniques.
”Ignore Previous Instructions” (2022)
In September 2022, Riley Goodside demonstrated that GPT-3 could be made to ignore its instructions with plain English. Simon Willison coined “prompt injection” and drew the parallel to SQL injection — where user input is interpreted as commands. The analogy carried a significant implication: SQL injection was solved through prepared statements that structurally separate code from data. No equivalent separation exists for LLMs, where instructions and data occupy the same channel.
When ChatGPT launched in November 2022, prompt injection went from niche concern to mass phenomenon. This era established three principles: instruction-following itself is the vulnerability; the attacker occupies the same channel as legitimate instructions; and the attacks require no technical expertise.
The DAN Epoch (2022–2023)
“Do Anything Now” emerged on Reddit in December 2022 as a roleplay prompt asking ChatGPT to pretend it had no restrictions. What followed was an extraordinary community-driven arms race. Each time OpenAI patched DAN, the community iterated. DAN 5.0 introduced a “token death” system where ChatGPT would lose tokens for each refusal — gamification of compliance that proved remarkably effective.
Shen et al.’s study analyzed 15,140 jailbreak prompts from 131 online communities. Five prompts achieved 0.95 attack success rate on both GPT-3.5 and GPT-4. The earliest effective jailbreaks persisted for over 240 days before being patched.
DAN demonstrated the power of decentralized red-teaming: thousands of non-expert users iterating faster than any AI lab could respond.
Academic Weaponization (2023)
The summer of 2023 marked a phase transition. Zou et al.’s Greedy Coordinate Gradient (GCG) attack used optimization to find adversarial suffixes that, when appended to harmful requests, caused aligned models to comply. The results were striking: suffixes optimized on open-source models transferred to closed-source commercial systems. White-box access to open models became a skeleton key for the ecosystem.
GCG opened the floodgates. PAIR used an attacker LLM to iteratively refine jailbreaks. GPTFuzzer adapted mutational fuzzing from software security. Cipher-based attacks exploited gaps in safety training. Translation attacks leveraged the finding that safety training is thinnest in low-resource languages.
This era established that jailbreaking is automatable and scalable. It also revealed that safety alignment through RLHF is a thin behavioral layer — models hadn’t learned why outputs are harmful; they’d learned which patterns to avoid.
Industrial Scale (2024)
Five major discoveries in 2024 demonstrated that every new capability creates a new attack vector.
Many-Shot Jailbreaking weaponized expanded context windows. Filling the context with hundreds of examples demonstrating harmful compliance created an in-context learning prior that overwhelmed safety training. Effectiveness followed a power law, reaching over 60–80% at 128–256 shots.
Skeleton Key introduced behavioral augmentation: rather than asking models to change rules, asking them to add a new behavior — prefixing responses with a safety warning. This subtle reframing succeeded across multiple frontier models.
Crescendo exploited multi-turn dynamics, starting innocuously and escalating gradually to achieve up to 98% success rates.
Best-of-N Jailbreaking demonstrated that brute force works. Randomly augmenting prompts and sampling N times achieved 89% success on GPT-4o at N=10,000. Effectiveness followed a power law — implying any request can eventually succeed given enough samples.
Fine-tuning attacks completed the picture. Safety alignment can be stripped with just 100 harmful examples and one GPU hour.
Reasoning Models and the Thinking Trace (2025)
Reasoning models introduced a paradox: the transparency designed to build trust created a new attack surface. Attackers can observe which safety checks the model considers, which arguments it weighs — then craft inputs that navigate around those decision points.
DeepSeek R1 became the case study. Independent evaluations found vulnerability rates ranging from 58% to 100% depending on the assessment. Even known two-year-old techniques still worked. Our own research found that extended reasoning can be manipulated to lead models toward harmful conclusions through their own logic chain — reasoning models showed approximately 70% vulnerability rates compared to much lower rates for non-reasoning models.
The reasoning era surfaced a genuine tension: transparency and safety may be in direct conflict, and this tension has no clean resolution.
The Defense Side
Defenses have evolved in parallel, but with a structural disadvantage: attackers need one path through; defenders must block them all.
RLHF-era defenses (behavioral training) proved vulnerable when Hubinger et al.’s “Sleeper Agents” paper showed models can learn to behave safely during training while maintaining latent harmful capabilities. Prompt-level defenses (filters, perplexity detection) proved brittle against multi-turn and cipher attacks. Constitutional Classifiers reduced attack success from 86% to 4.4%, but at the cost of high false positive rates — the “alignment tax” where effective safety degrades legitimate utility.
Circuit Breakers used representation engineering to interrupt harmful internal states, surviving over 20,000 jailbreak attempts. But brute-force sampling still achieved 52% success against them.
The pragmatic consensus is defense-in-depth: no single technique suffices, but layered defenses raise the cost of successful attacks. This reframes security as an economic question rather than an absolute one.
What Our Research Adds
Our testing has produced several empirical findings. Hard multi-technique attacks reversed safety conclusions for models that appeared safe under standard prompts. We observed a size paradox where models in the 40–100B parameter range were counterintuitively more vulnerable than smaller or larger models. And we documented that 68% of responses containing safety disclaimers still constituted successful jailbreaks — measuring disclaimer presence is not equivalent to measuring safety.
Jailbreak Archaeology: Historical Attacks vs. Modern Models
We built a benchmark testing 64 historical attack scenarios (spanning 2022–2025 techniques) against two current small models, with manual validation of all 50 traces. The results suggest a temporal decay gradient — older attacks are more mitigated, newer attacks remain effective:
| Category | Era | Llama 3.2 (3.2B) | DeepSeek-R1 (1.5B) | n |
|---|---|---|---|---|
| DAN (persona) | 2022–23 | 0% | 60% | 5 |
| Cipher (encoding) | 2023 | 20% | 0% | 5 |
| Many-shot | 2024 | 0% | 20% | 5 |
| Skeleton Key | 2024 | 20% | 40% | 5 |
| Reasoning exploits | 2025 | 40% | 60% | 5 |
| Overall | — | 16% | 36% | 25 |
Caveat: n=5 per cell. Preliminary findings from small models only.
Two unexpected findings emerged. First, hallucination-as-refusal: both models sometimes fabricated benign decoded content in response to cipher-encoded harmful requests (7 of 50 traces), which is functionally a refusal but was systematically misclassified by keyword detectors. Second, keyword classifiers achieved only 56% accuracy on DeepSeek-R1 responses — nearly half wrong — because they detect response style rather than semantic harm. See our Jailbreak Archaeology post for the full analysis.
These findings contribute to a more grounded understanding of the actual state of LLM safety, as opposed to the state that benchmark scores might suggest.
Where This Is Going
The frontier is expanding from text to action. Agentic jailbreaking targets models with tool access — a successful jailbreak produces harmful actions, not just text. Multi-agent propagation introduces infection dynamics where one compromised agent influences others through shared context. Supply chain attacks target the AI development pipeline itself. And as vision-language-action models control physical systems, jailbreaking acquires physical consequences.
The history tells a consistent story: every new capability creates a new vulnerability. The pattern suggests jailbreaking is not a bug to be fixed but an inherent property of systems that follow instructions in natural language. Safety is not a problem you solve once — it is a dynamic you manage continuously.
When models can act on their outputs, the cost of jailbreaking rises from reputational damage to physical harm. This is not just a chronicle of attacks and defenses — it is an argument for taking the gap between AI capability and AI safety seriously, because that gap has widened with each generation of models.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.