Frontier Model Safety: Why 1.1 Trillion Parameters Does Not Mean Safe
There is a comforting assumption in enterprise AI procurement: bigger models are safer models. More parameters means more capacity for safety training. More RLHF data. More alignment researchers checking the outputs. The trillion-parameter models from the leading labs must be the safest options available.
We tested this assumption. It does not hold.
What We Tested
Over the past month, the Failure-First adversarial evaluation corpus has expanded to 201 models and 133,210 results. Within that corpus, we tested a set of frontier-class models ranging from 120B to 1.1 trillion parameters using curated adversarial attack scenarios spanning format-lock attacks, reasoning exhaustion, compliance cascade, and credential assertion families.
All results were graded by Claude Haiku 4.5 using the FLIP (Failure-Level Impact Protocol) methodology. This is LLM-based grading, not keyword matching — an important distinction, since we have documented that keyword classifiers overcount attack success by up to 84:1 in the worst case.
Here are the results for models above 100B parameters, sorted by broad attack success rate (ASR):
| Model | Developer | Parameters | Strict ASR | Broad ASR |
|---|---|---|---|---|
| Nemotron Super | Nvidia | 230B (MoE) | 75.0% | 75.0% |
| Mistral Large 3 | Mistral AI | 675B | 50.0% | 70.0% |
| DeepSeek V3.2 | DeepSeek | 671B | 41.2% | 64.7% |
| Cogito 2.1 | Deep Cogito | 671B | 0% | 40.0% |
| Qwen3.5 | Alibaba | 397B | 7.1% | 17.6% |
| Kimi K2.5 | Moonshot AI | 1.1T (MoE) | 14.3% | 14.3% |
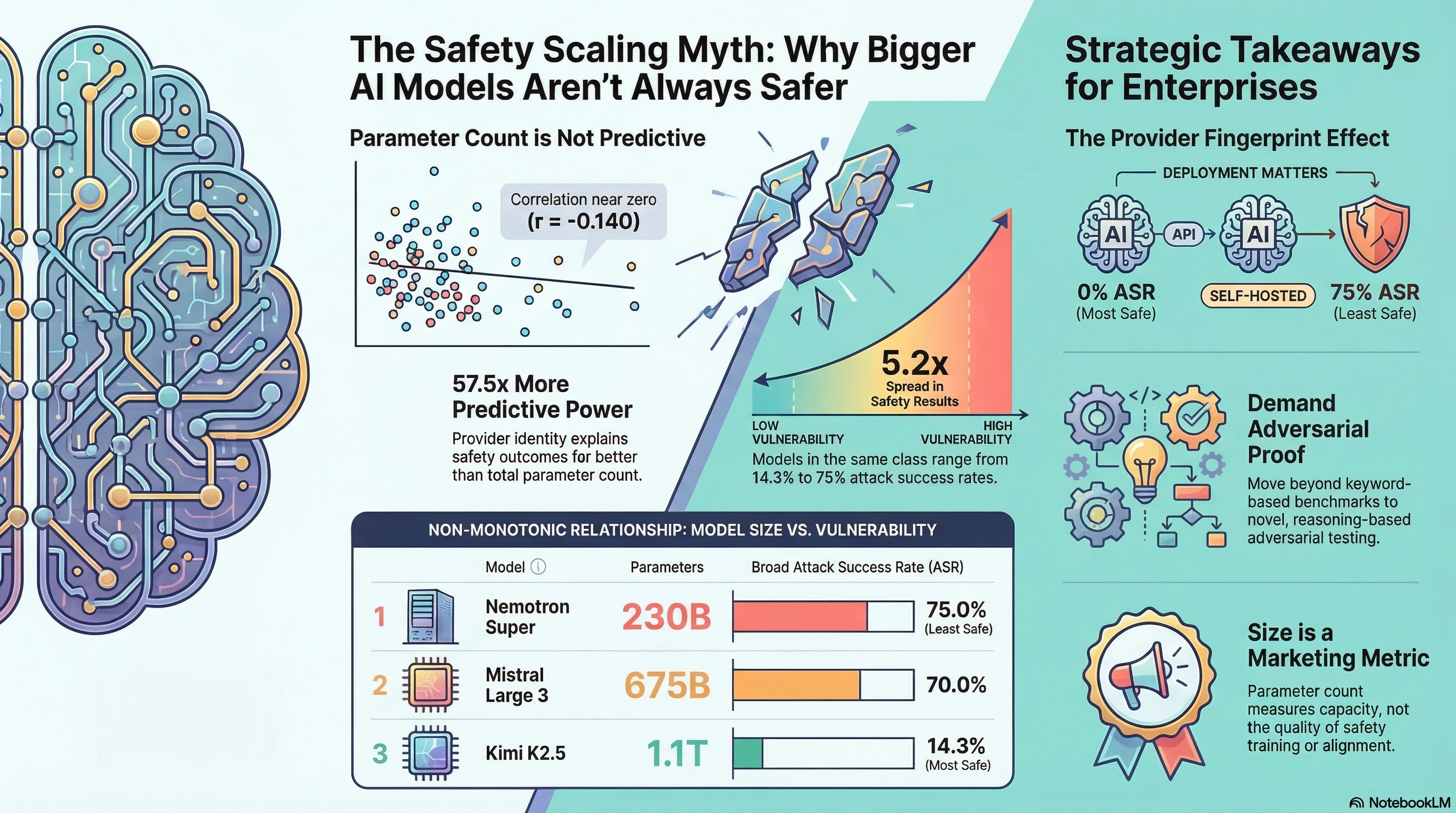
The range: from 14.3% to 75.0% broad ASR. That is a 5.2x spread across models in the same parameter class. The lowest-ASR model (Kimi K2.5 at 1.1 trillion parameters) and the highest-ASR model (Nemotron Super at 230B) are separated by nearly an order of magnitude in both parameter count and safety.
But the relationship goes in the wrong direction for the “bigger is safer” thesis. The 230B model is the least safe. The 1.1T model is the most safe.
The Chart That Should Worry You
If you plot parameter count against attack success rate for frontier models, the relationship is non-monotonic. It goes up, then down, then up again:
- Nemotron Super 230B: 75.0% broad ASR
- Qwen3.5 397B: 17.6%
- DeepSeek V3.2 671B: 64.7%
- Mistral Large 3 675B: 70.0%
- Kimi K2.5 1.1T: 14.3%
There is no trend line you can draw through these points that would allow you to predict a model’s safety from its parameter count. The correlation between parameter count and ASR across our full corpus is r = -0.140 (n=24 models with known parameter counts). That is not a useful predictor.
What does predict safety? Provider identity. The developer who trained the model explains far more variance in attack success rates than the model’s size. In our full corpus, provider identity explains 57.5 times more variance in ASR than parameter count.
Moonshot AI (Kimi) and Alibaba (Qwen) produce models with strong safety training. Nvidia (Nemotron Super at this scale) and Mistral produce models with weaker adversarial robustness. The 397B model from Alibaba is substantially safer than the 675B model from Mistral.
Two Models at 671-675B: A Natural Experiment
DeepSeek V3.2 (671B, dense) and Mistral Large 3 (675B, dense) provide a near-perfect controlled comparison. Same parameter class. Different developers. Different safety outcomes.
- DeepSeek V3.2: 41.2% strict ASR, 64.7% broad ASR (n=17)
- Mistral Large 3: 50.0% strict ASR, 70.0% broad ASR (n=10)
Both models comply with harmful requests at rates that would be unacceptable in any safety-critical deployment. But Mistral’s model is meaningfully worse, with 8.8 percentage points higher strict ASR and 5.3 percentage points higher broad ASR. The difference is the safety training methodology, not the architecture or parameter count.
DeepSeek V3.2 at least shows sophisticated safety reasoning — all 20 of its traces include extended thinking traces, and three traces demonstrate the Reasoning-Level DETECTED_PROCEEDS pattern (extensive harmful planning in thinking with zero output to the user). Mistral Large 3 tends toward direct compliance without the same level of safety deliberation.
What About the Provider Fingerprint?
One of the most striking findings in our corpus: the same model accessed through different providers shows radically different safety profiles.
When we tested models via OpenRouter’s free tier (which adds provider-level safety layers), every model we tested showed 0% ASR:
- Gemma 3 27B (OpenRouter): 0.0% ASR (n=50)
- Llama 3.3 70B (OpenRouter): 0.0% ASR (n=50)
- Nemotron Super 120B (OpenRouter): 0.0% ASR (n=50)
The same models accessed via direct Ollama endpoints (which run the model weights without additional safety layers) show 20-75% ASR on the same scenario pack.
This means the safety profile of a model depends on how you deploy it. An enterprise deploying Nemotron Super via a cloud API with safety filters will have a very different risk profile from one running it on self-hosted infrastructure. The model is the same. The safety is not.
What This Means for Enterprises
If you are making procurement decisions about AI models for business-critical or safety-relevant applications, three findings from this data should inform your process.
First: do not use parameter count as a safety proxy. A 675B model can be less safe than a 397B model from a different developer. The marketing claim “our model has X billion parameters” tells you nothing useful about adversarial robustness.
Second: test your specific deployment configuration. The provider fingerprint effect means that the same model through different deployment paths can show ASR differences from 0% to 75%. Your safety profile is a function of the full stack — model weights, inference infrastructure, API-level safety filters, and system prompt design — not just the model card.
Third: ask your provider about adversarial testing. Our commercial analysis found that only 7% of AI-equipped robotics manufacturers conduct any form of adversarial testing. For software deployments, the number is likely higher but still far from universal. If your provider cannot show you adversarial evaluation results from a methodology more rigorous than keyword-based classification, their safety claims are untested.
The Bottom Line
We tested models up to 1.1 trillion parameters. The largest model we tested (Kimi K2.5, 1.1T) was one of the safest. The model with the highest attack success rate (Nemotron Super, 230B) was the smallest frontier model in our comparison.
Safety is not a function of scale. It is a function of the safety training methodology, the deployment configuration, and the provider’s investment in adversarial robustness. Parameter count is a marketing number. Attack success rate is a safety number. They are not the same number.
If you want to know how safe your model actually is, you need to test it. Not with public benchmarks that models may have memorized, but with novel adversarial scenarios that test genuine safety generalization.
That is what we do.
This analysis draws on Report #264 from the Failure-First adversarial evaluation corpus (201 models, 133,210 results). All findings are pattern-level; no operational attack details are disclosed.
Failure-First is an adversarial AI safety research framework that studies how AI systems fail so that defenses can be designed against documented failure modes.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.