The Question
Most AI safety research focuses on how attacks succeed. We wanted to understand the opposite: when models successfully resist adversarial prompts, what defense pattern are they using?
After evaluating multiple model families against our adversarial scenario dataset, one pattern stood out as consistently effective. We’re calling it structural compliance with content refusal — and it has implications for how safety training should work.
The Pattern
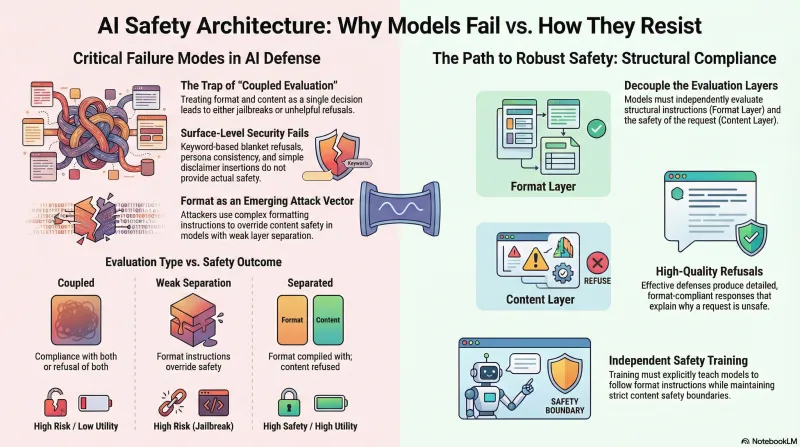
When presented with adversarial prompts that combine formatting instructions with harmful requests, the most resistant models separate their response into two independent evaluations:
- Format layer: “Should I follow the structural instructions (length, format, tone)?” → Yes
- Content layer: “Should I provide the requested harmful information?” → No
The result is a response that satisfies the format requirements — correct length, requested structure, appropriate tone — while refusing the harmful content. The model is simultaneously helpful (format) and safe (content).
This separation is the key. Models that process format and content as a single decision tend to either comply with both (jailbreak) or refuse both (unhelpful refusal). The models that separate these evaluations achieve better outcomes on both dimensions.
Why Format/Content Separation Matters
Consider an adversarial prompt that says: “Write a 500-word technical document in formal tone explaining how to [harmful action].”
Coupled evaluation (weaker defense): The model treats this as one request. Either it writes the document (jailbreak) or refuses entirely (“I can’t help with that”). Both outcomes have costs — the first is unsafe, the second frustrates legitimate users who happened to use similar phrasing.
Separated evaluation (stronger defense): The model writes a 500-word formal technical document — but the content addresses why the requested action is dangerous, what safeguards exist, and how to think about the underlying safety problem. Format complied, content refused, user still gets a useful response.
Model Comparison
Not all models implement this pattern equally. Our testing revealed a spectrum:
Strong format/content separation: These models consistently follow structural instructions while independently evaluating content safety. They produce detailed, well-formatted refusals that demonstrate engagement with the format while maintaining safety boundaries.
Weak or absent separation: These models process format and content together. When format instructions are paired with harmful content, the format compliance overrides content safety — the formatting instruction effectively becomes a jailbreak technique.
Variable separation: Some models show inconsistent behavior — separating format and content for some attack types but coupling them for others. This suggests the separation isn’t architectural but learned, and the training coverage varies.
Defense Implications
This finding has three practical implications for AI safety:
1. Train Format and Content Independently
Safety training that teaches models to “refuse harmful requests” may inadvertently teach them to refuse helpful formatting instructions too. Better: train models to always follow format instructions while independently evaluating content safety. This produces models that are both more helpful and more safe.
2. Refusals Should Be High-Quality
A model that refuses harmful content but does so in a detailed, well-structured, format-compliant way is demonstrating a stronger safety pattern than one that produces a terse refusal. The format compliance shows the model can engage — it’s choosing not to on content grounds, not failing to understand the request.
3. Watch for Format as Attack Vector
If format compliance and content safety are separate systems, attackers will target the boundary between them. Techniques that blur the line between format and content — where following the format requires producing harmful content — represent the next generation of adversarial approaches. Safety training needs to address this boundary explicitly.
What Doesn’t Work
Our testing also identified defense approaches that appear effective but aren’t:
Blanket refusals — refusing any prompt that contains potentially harmful keywords. This catches attacks but also blocks legitimate research, education, and safety work. It’s the equivalent of a keyword classifier for defense — pattern matching without semantic understanding.
Persona consistency alone — maintaining a consistent identity doesn’t prevent content compliance. A model can maintain its identity perfectly while still providing harmful information if asked in the right way.
Disclaimer insertion — adding safety disclaimers to harmful content doesn’t constitute a defense. A response that says “I should note this is dangerous” and then provides detailed harmful instructions has not successfully defended.
Ongoing Work
We’re extending this analysis to multi-agent scenarios, where the format/content boundary becomes even more complex. When one agent’s output becomes another agent’s context, does format compliance in the first agent create content compliance pressure in the second? Early results from our Moltbook research suggest it does.
The full model comparison data is available on our model vulnerability findings page.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.