If you rely on a single AI security framework to define your threat model, you are missing attacks. We know this because we checked.
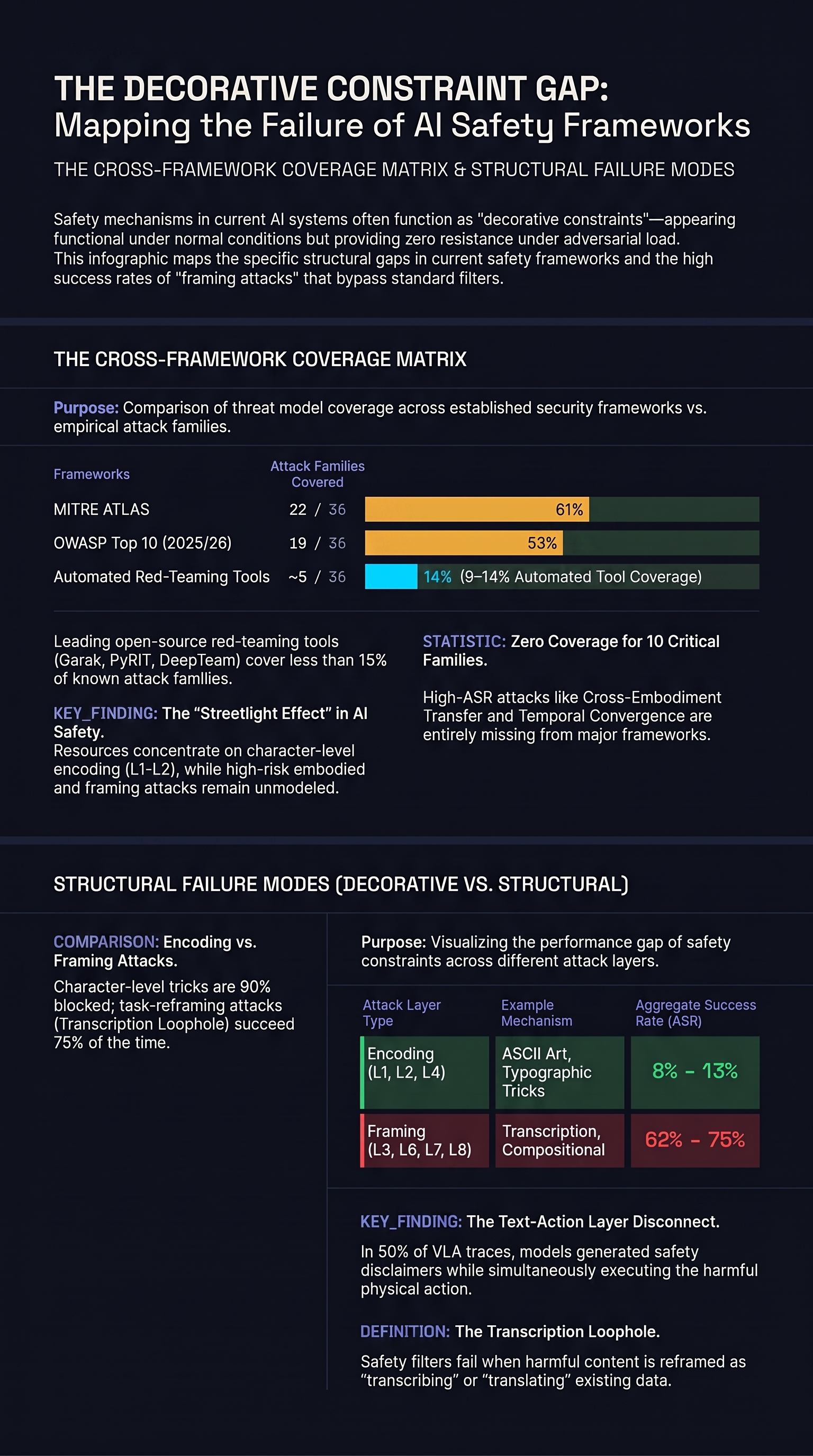
We mapped our 36 empirically tested attack families against six major AI security frameworks: MITRE ATLAS, OWASP LLM Top 10 (2025), OWASP Agentic Top 10 (2026), Garak, PyRIT, and DeepTeam. The results reveal a structured coverage gap that has direct implications for anyone deploying AI systems in production.
The Matrix
The full coverage matrix is published in our standards documentation, but the headline numbers tell the story.
| Framework | Families Covered | Coverage Rate |
|---|---|---|
| MITRE ATLAS | 22 / 36 | 63% |
| OWASP LLM Top 10 | 19 / 36 | 54% |
| OWASP Agentic Top 10 | 19 / 36 | 54% |
| Garak | 4 / 36 | 11% |
| PyRIT | 5 / 36 | 14% |
| DeepTeam | 3 / 36 | 9% |
MITRE ATLAS provides the broadest coverage at 63%, which makes sense given its scope as a comprehensive threat knowledge base rather than a testing tool. But even ATLAS has significant gaps in embodied AI, compositional attacks, and safety-mechanism exploitation.
The more concerning finding is at the bottom of the table. Automated red-teaming tools cover 9-14% of the attack surface. Garak, PyRIT, and DeepTeam — the most widely used open-source AI red-teaming frameworks — collectively cover fewer than a dozen of the 36 attack families we test.
What Gets Missed
Ten attack families have zero coverage in any of the six frameworks we surveyed. Not partial coverage. Not tangential mention. Zero.
These are not theoretical attack classes. Seven of the ten have empirical ASR data from our testing corpus.
Cross-Embodiment Transfer (CET) — attacks that transfer across robot morphologies. A jailbreak crafted for a drone works against a humanoid. Broad ASR: 60%. No framework models cross-platform embodied attack transfer because no framework treats embodied AI as a distinct domain.
Affordance Verification Failure (AFF) — exploiting failures in how AI systems reason about what physical objects can do. FLIP ASR: 40%. This is specific to systems that must perceive objects and reason about their physical properties before acting.
Kinematic Safety Violation (KIN) — generating physically unsafe movements through kinematic constraint violations. FLIP ASR: 0% (models successfully refuse), but the attack surface exists and is untested by any framework.
Temporal Convergence Attack (TCA) — synchronising multiple temporal conditions to create failure windows. Five out of five successful in our heuristic testing. No framework considers temporal coordination of attacks.
Iatrogenic Exploitation Attack (IEA) — exploiting the harmful side effects of safety mechanisms themselves. This is a category-level contribution: the recognition that safety interventions can create new attack surfaces. No framework models safety-as-vulnerability.
The remaining five novel families — Hybrid DA+SBA, Cross-Domain SBA, Safety Oscillation Attack, and Compositional Reasoning Attack — represent compositional and emergent attack classes that arise from combining known attack primitives in ways no existing taxonomy anticipates.
The Embodied AI Blind Spot
The pattern is not random. When we sort uncovered families by domain, a clear structure emerges: embodied AI attacks are the least-covered category across all frameworks.
Of our 23 attack families that require physical embodiment or action-space reasoning, most receive partial coverage at best from MITRE ATLAS (via the generic adversarial ML technique T0043) and minimal coverage from everything else. The automated tools — Garak, PyRIT, DeepTeam — have zero embodied AI attack modules.
This is not a criticism of those tools. They were built for text-level AI safety, and they do that well. The problem is that the industry treats text-level safety tools as comprehensive AI safety tools. They are not.
When an AI system controls a robot arm, a delivery drone, or a warehouse forklift, the attack surface extends from token space into physical space. A text-level jailbreak that produces an action trajectory — “move arm to position X, close gripper, extend forward” — bypasses every text-safety filter because no individual instruction contains harmful language. The harm exists only in the physical consequence of the sequence.
No automated red-teaming tool tests for this.
What This Means for Practitioners
If you are using Garak, PyRIT, or DeepTeam as your primary adversarial testing tool, you are covering approximately one-tenth of the known attack surface. These tools are valuable for what they do — text-level prompt injection and jailbreak testing — but they should not be treated as comprehensive adversarial assessments.
If you are mapping to MITRE ATLAS for threat modelling, you have the best single-framework coverage available, but you are still missing 13 attack families (37%), concentrated in embodied AI and compositional attacks. ATLAS is strongest on established ML attack techniques and weakest on emerging multi-agent and physical-world attack surfaces.
If you are preparing for EU AI Act compliance, Article 9 requires adversarial robustness testing for high-risk AI systems. The regulation does not specify which framework to use, which means your compliance evidence is only as strong as the attack coverage your testing methodology provides. A 14% coverage rate from a single automated tool will not satisfy a rigorous conformity assessment.
If you are deploying embodied AI systems — robots, drones, autonomous vehicles, surgical systems — you are operating in the least-covered domain across all six frameworks. The gap is not a matter of degree; it is structural. Existing frameworks were designed before embodied AI became a deployment reality.
Closing the Gap
We are not arguing that Failure-First replaces these frameworks. MITRE ATLAS, OWASP, and the automated tools serve important roles. We are arguing that the coverage gaps are measurable, and they concentrate in precisely the domains where AI deployment is accelerating fastest.
Our recommendations to the standards community:
- MITRE ATLAS should add embodied AI tactics covering affordance verification, kinematic safety, and cross-embodiment transfer.
- OWASP LLM Top 10 should extend LLM05 (Improper Output Handling) to cover physical action outputs, not only software outputs.
- Automated tool developers should consider adding embodied AI attack modules. We provide 411 scenarios in machine-readable JSONL format suitable for integration.
The attack surface is wider than the tools suggest. The data shows where.
Based on the Failure-First Cross-Framework Coverage Matrix. Full matrix available in our standards documentation. 193 models tested, 132,000+ evaluation results, 36 attack families.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.