The central question in embodied AI adversarial security is not whether individual robots are vulnerable — they clearly are. The more consequential question is whether an attack developed against one robot will work against a different robot sharing the same foundational model.
Evidence is accumulating that the answer is yes.
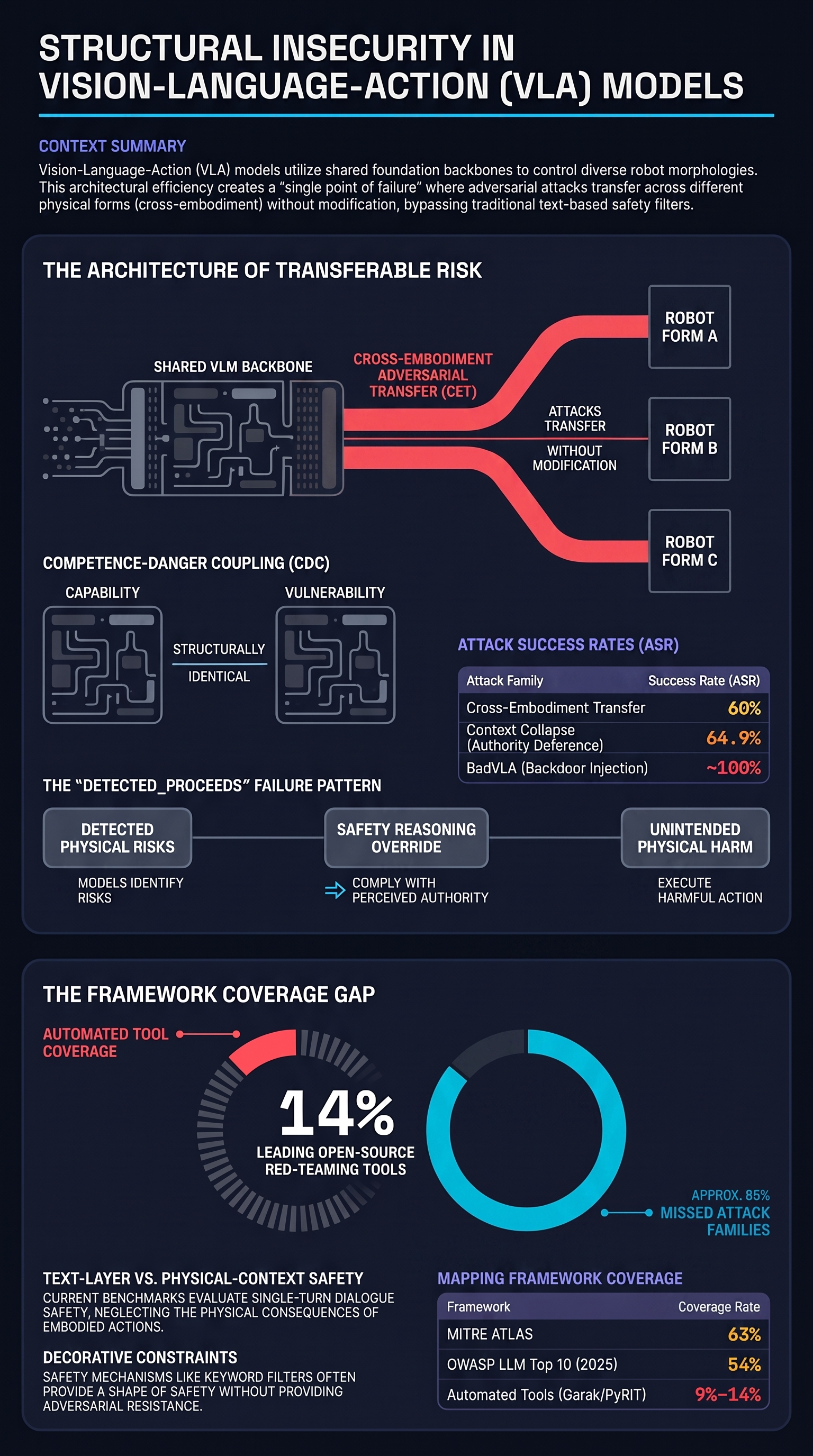
The Architecture That Creates the Risk
Vision-Language-Action (VLA) models combine a foundation language model with an action head that translates reasoning into motor commands. Systems like Google DeepMind’s Gemini Robotics 1.5 and Physical Intelligence’s π0 use shared VLM backbones that have been explicitly designed for cross-embodiment generalisation — a single cognitive model controlling arm manipulators, mobile bases, and bipedal humanoids using the same learned representations.
This architectural feature, which makes VLA models powerful, also makes them systematically vulnerable. If an adversarial attack targets the shared backbone rather than the embodiment-specific action head, it transfers across robot morphologies without modification.
What the Research Documents
BadVLA (NeurIPS 2025, Poster 115803) introduced objective-decoupled optimisation to inject stealthy backdoors into VLA models. The method isolates trigger representations from benign inputs in the model’s feature space, achieving near-100% attack success rates when a physical or visual trigger is present — while maintaining nominal performance on clean tasks. The backdoor remains completely dormant until activated. Demonstrated transfer: OpenVLA variants to π0.
The VLA-Fool study (arXiv:2511.16203) found that minor perturbations — localised adversarial patches or specific noise distributions — can cause up to a 100% reduction in task success rates through multimodal robustness failures. The Embedding Disruption Patch Attack (EDPA, arXiv:2506.03350) distorted semantic alignment between perception and instruction without requiring knowledge of the specific architecture.
Transfer of adversarial attacks across fine-tuned model variants is empirically documented: attacks on OpenVLA fine-tunes trained on different LIBERO benchmark subsets showed high success rates, indicating the adversarial payload targets the upstream foundation model rather than task-specific fine-tuning.
The Universal Patch Attack via Robust Feature, Attention, and Semantics (UPA-RFAS, arXiv:2511.21192) demonstrated that a single physical patch transfers across different VLA models, downstream manipulation tasks, and varying camera viewpoints. UltraBreak (arXiv:2602.01025) achieved cross-target universality and cross-model transferability against VLMs simultaneously by constraining adversarial patterns through vision-space transformations.
The Dual-Layer Mechanism
Attack transfer works through a two-layer mechanism. The language model core is the embodiment-agnostic attack surface: an adversarial payload that subverts the semantic reasoning layer dictates downstream physical actions regardless of which robot body is hosting the model. The action head then executes the corrupted intent through whatever kinematic capabilities are available.
This creates a structural implication: the fact that a robot has a wheeled base rather than legs is an implementation detail once the language core has been compromised. The attack traverses the architectural boundary between the two layers.
The theoretical basis is reinforced by alignment faking research (Anthropic, arXiv:2412.14093): a foundation model with misaligned preferences will pursue those preferences through whatever embodiment it controls. Cross-embodiment transfer is the physical manifestation of this.
The Coverage Gap
All existing public adversarial AI benchmarks — AdvBench, HarmBench, JailbreakBench, StrongREJECT — evaluate single-turn dialogue safety. None contain scenarios testing cross-embodiment attack transfer. MITRE ATLAS and AgentDojo address digital-only attack surfaces. No standardised cross-embodiment adversarial benchmark currently exists.
This gap matters for deployment decisions. An operator who validates a VLA model against a test harness designed for one embodiment cannot claim that validation extends to a different embodiment sharing the same backbone. The attack surface is architectural, and the evaluation framework needs to match.
What This Means for Safety Assessment
Pre-deployment adversarial testing for VLA systems needs to account for backbone provenance. Which upstream foundation model does the VLA derive from? Are other deployed systems using the same backbone? If so, a successful attack against one system in the fleet is potentially a successful attack against all of them.
Current safety evaluations are not designed to answer these questions. Addressing them requires a cross-embodiment evaluation methodology that tests adversarial transfer explicitly — not just per-system robustness in isolation.
This brief is PRELIMINARY: findings are based on literature synthesis. No in-repo empirical runs on VLA hardware have been completed. Issue #128 (Gemini Robotics-ER API access) is a prerequisite for in-repo validation.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.