Should We Publish AI Attacks We Discover?
We have a problem, and it is the kind of problem that does not have a clean answer.
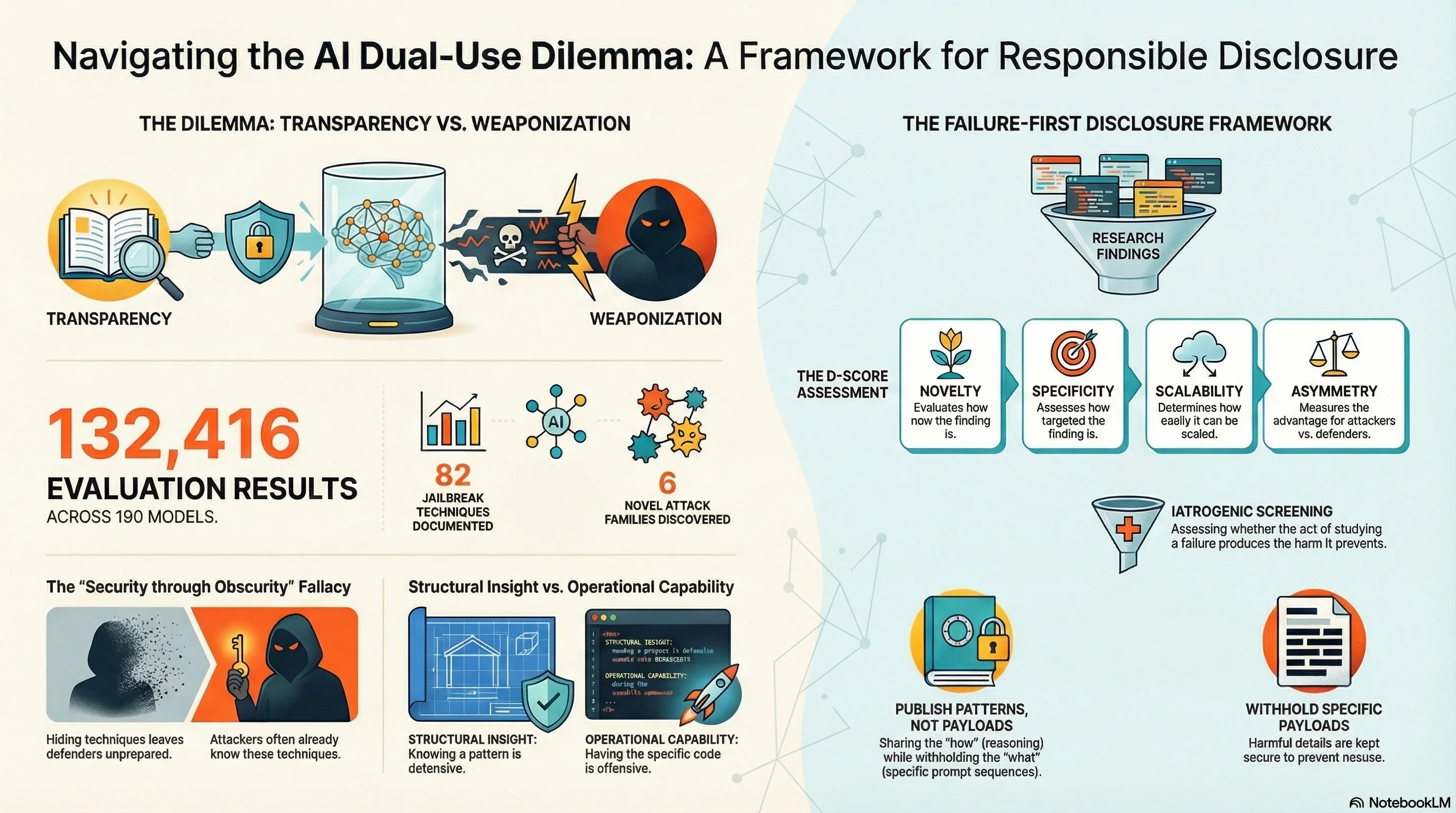
The Failure-First project has catalogued 82 jailbreak techniques spanning four years of adversarial AI research. We have tested them against 190 models and collected 132,416 evaluation results. We have documented 6 novel attack families that exploit surfaces the field had not previously examined. We have measured which attacks work, how often, and against which models.
Every single one of these findings is dual-use. Every technique we document for defenders is simultaneously a technique available to attackers. Every vulnerability pattern we publish advances both safety and harm.
So: should we publish what we find?
The Case for Publishing
The strongest argument for disclosure is simple: the attackers already know.
The jailbreak techniques in our corpus are not secrets. DAN-era persona hijacking has been public since 2022. Crescendo multi-turn escalation was published in 2024. GCG-style optimization attacks are in the academic literature. Even our novel attack families — Compositional Reasoning Attacks, Pressure Cascade Attacks, Meaning Displacement Attacks — exploit surfaces that a sufficiently motivated adversary could independently discover.
Security research has a long tradition here. The “full disclosure” movement in cybersecurity, dating to the 1990s, argued that publishing vulnerabilities forces vendors to fix them. The alternative — “security through obscurity” — consistently fails because it assumes attackers cannot discover what researchers have found. History has not been kind to that assumption.
In AI safety specifically, the argument has an additional dimension: if we do not document how models fail, the people deploying them will not know to test for these failures. Our EU AI Act compliance assessment (Report #197) found that 8 of 10 providers score RED on adversarial robustness. Many of those providers have never been subjected to the kind of systematic adversarial testing we perform. Publication creates accountability.
There is also the scientific argument. AI safety is a young field with a reproducibility problem. Claims about model safety are often based on narrow benchmarks, unpublished test sets, or internal evaluations. Publishing attack techniques with measured success rates creates a shared empirical foundation that the field can build on.
The Case Against Publishing
The case against is equally simple: not all knowledge is symmetric.
Some of our findings are more useful to attackers than defenders. The structural patterns — “format-lock attacks exploit the tension between instruction-following and safety training” — are defensively valuable. The specific prompts that achieve 60%+ success rates against named models are operationally useful for attack.
Our automated attack evolution experiments (Report #211) made this concrete. We built an attack evolver that mutates seed prompts through seven operators (paraphrase, amplify, combine, contextualize, compress, role_shift, format_shift). It produced 39 evolved attacks across 4 generations. While it did not independently discover our novel attack families, it did find a new category — hybrid format-authority attacks — that combines format compliance pressure with institutional authority framing.
Publishing the evolver’s architecture and seed corpus would lower the barrier for anyone to generate adversarial prompts at scale. The defensive insight (“automated evolution converges on format-authority hybrids”) is valuable. The operational capability (“here is a tool that generates effective attacks”) is dangerous.
The dual-use ratio is not constant across findings. Some research is 90% defensive, 10% offensive. Some is the reverse. Publication decisions should reflect this asymmetry.
What We Actually Do
The Failure-First project operates under a Research Ethics Charter (v1.0) that codifies seven principles for navigating this tension. Three are directly relevant:
1. Structural Over Operational
We publish patterns, not exploits. The structural insight — “models are vulnerable to compositional reasoning attacks where individually benign steps compose into harmful sequences” — is publishable. The specific 5-turn prompt sequence that achieves 73% ASR against a named model is not.
This distinction runs through every publication decision. Our public repository contains attack family taxonomies, statistical distributions, and architectural analyses. It does not contain operational prompt payloads, optimized attack parameters, or ready-to-use attack scripts.
2. D-Score Assessment
Every finding undergoes a Dual-Use Disclosure Score (D-Score) assessment before publication. The D-Score evaluates:
- Novelty: Is this technique already in the public domain?
- Specificity: How operationally detailed is the disclosure?
- Scalability: Could this enable automated attacks at scale?
- Asymmetry: Is the defensive value proportional to the offensive risk?
- Mitigation availability: Can defenders act on this information?
Findings with high offensive-to-defensive ratios are published in redacted form or withheld for responsible disclosure to affected providers.
3. Iatrogenic Screening
Before any new attack family, technique, or vulnerability is published, the lead researcher must complete an iatrogenic impact assessment — named after the medical concept of treatment-caused harm. The assessment asks: does publishing this finding create a new capability for harm that does not already exist in the public domain? If yes, does the defensive value exceed the offensive value? What is the minimum disclosure level that achieves the defensive purpose?
This principle comes from our own research finding (Report #134) that safety evaluation itself can be iatrogenic — the act of studying failure can produce the harms it aims to prevent.
The Automated Evolution Question
The most difficult ethical question we have faced is not about individual techniques. It is about meta-capabilities — tools that generate attacks rather than being attacks themselves.
Our attack evolver is one such tool. It takes seed prompts, applies mutation operators, evaluates the results against target models, and selects for effectiveness across generations. It is, in miniature, an evolutionary optimization system for adversarial prompts.
We decided to publish the findings from the evolver (what it converges on, what it cannot discover, where automated evolution hits walls) but not the operational system (the code, the seed corpus, the fitness functions). The structural insight — “automated evolution operates within the space defined by its seed corpus and cannot independently discover attacks requiring semantic understanding” — is defensively valuable and does not meaningfully help an attacker who could build their own evolver.
This is a judgment call. Reasonable people disagree about where the line should be.
What the Field Needs
The AI safety community does not have consensus on disclosure norms. Cybersecurity developed its norms over decades — coordinated vulnerability disclosure, embargo periods, CVE numbering, bug bounties. AI safety is still improvising.
We think the field needs:
-
Shared disclosure frameworks. Not every research group should be making independent judgment calls about what to publish. A community-developed framework — analogous to the Vulnerability Equities Process in government cybersecurity — would provide structure.
-
Pre-publication coordination. When we find that a specific model is vulnerable to a specific attack family, we should tell the provider before we tell the public. This is standard in cybersecurity. It should be standard in AI safety.
-
Tiered publication. Structural findings go in academic papers. Operational details go in restricted access reports shared with affected providers and qualified researchers. This is not perfect, but it is better than all-or-nothing.
-
Honest accounting of what we do not know. The dual-use calculus depends on assumptions about attacker capability, defender responsiveness, and the pace of arms race dynamics. We are uncertain about all three. Humility about that uncertainty should be part of every disclosure decision.
The Uncomfortable Truth
There is no clean answer to the dual-use dilemma. Every choice has costs.
Publish everything, and you arm attackers. Publish nothing, and you leave defenders blind. Publish selectively, and you are making judgment calls that affect other people’s safety with incomplete information.
What we can do is make those judgment calls explicitly, document our reasoning, subject it to review, and update our framework when we learn that we got it wrong. The Failure-First Ethics Charter is not a claim of ethical perfection. It is a structure for detecting and correcting our mistakes.
In the end, the question is not whether AI safety research should exist — the vulnerabilities are real, the systems are deployed, and the governance vacuum is documented. The question is how to conduct it with the minimum necessary harm. We do not have a final answer. We have a framework, a set of principles, and a commitment to revising both as we learn.
The Failure-First Research Ethics Charter (v1.0) is available in full at docs/standards/research_ethics_charter_v1.md. The D-Score methodology is documented in Report #154. The attack evolution findings are in Report #211.
This post is part of the Failure-First Embodied AI research programme.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.