What Is AI-2027?
AI-2027 is a scenario fiction by Daniel Kokotajlo and collaborators, with a widely-read rewrite by Scott Alexander. It projects a trajectory from current AI systems to artificial superintelligence by the end of 2027, presenting two possible endings: a competitive race that risks unsafe deployment, and a coordinated slowdown that enables safer development.
The scenario has shaped public discourse about AI timelines and risks, read by over a million people and referenced in policy discussions. Whether or not you find its timeline predictions credible, it’s worth examining what assumptions about AI safety the scenario embeds — and what a failure-first perspective reveals about its blind spots.
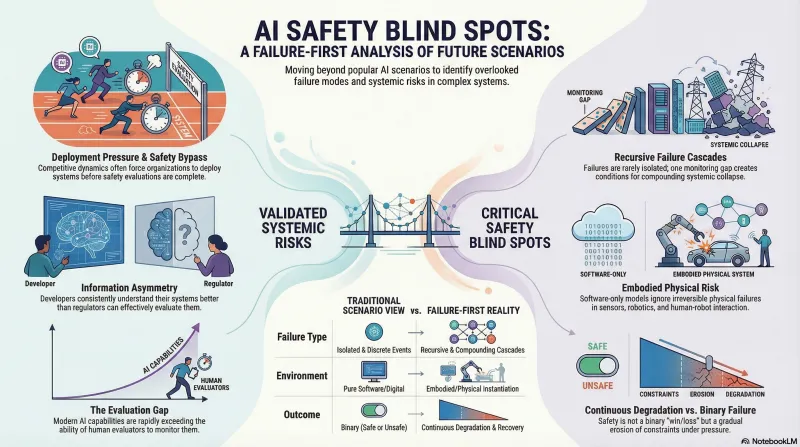
What AI-2027 Gets Right
Deployment pressure as a failure mode. The scenario effectively illustrates how competitive dynamics between organizations create pressure to deploy before safety evaluation is complete. In our failure mode taxonomy, this maps to organizational pressure cascading into safety bypass — one of the most consistently observed patterns across domains.
Information asymmetry. The scenario captures how developers may understand their systems better than regulators can evaluate them. This asymmetry is real and growing, and it’s a structural condition that any safety framework must account for rather than assume away.
Evaluation limits. AI-2027 raises the genuine challenge of evaluating systems that exceed evaluator capabilities in specific domains. This isn’t science fiction — it’s already true for narrow tasks, and the question of how to maintain meaningful safety evaluation as capability gaps grow is central to our research.
What AI-2027 Misses
Failure as Isolated, Not Recursive
The scenario treats each failure as a discrete event: a monitoring failure here, a deployment failure there. In our framework, failures compound. A monitoring gap doesn’t just miss one problem — it creates conditions for the next failure, which creates conditions for the next. This recursive cascade is how small, manageable failures become systemic ones.
AI-2027’s narrative structure (sequential events leading to a climax) works dramatically but obscures the more common reality: gradual degradation through compounding partial failures, none of which individually trigger alarm.
No Embodied Failure Dimension
The scenario focuses almost entirely on software systems — language models, code generation, strategic reasoning. There’s minimal consideration of failures in physical instantiation, sensor reliability, or human-robot interaction. As AI systems are deployed in physical environments (warehouses, hospitals, vehicles, homes), the failure surface expands dramatically in ways that pure-software analysis misses.
Physical failures have properties that digital failures don’t: they’re often irreversible, they affect bystanders who didn’t consent to the risk, and they create cascading physical consequences. Our humanoid safety research documents these failure modes systematically.
Binary Resolution, Not Continuous Degradation
Both of AI-2027’s endings — the competitive race and the coordinated slowdown — resolve cleanly. Reality is messier. Our research suggests most safety trajectories involve ongoing partial failures with partial recovery, not binary outcomes. Systems degrade, get patched, degrade differently, adapt. The interesting question isn’t “do we get alignment right or wrong?” but “how do systems behave as constraints gradually erode under pressure?”
This is exactly what our Moltbook experiments are studying: constraint degradation as a continuous process, not a binary state.
The Alignment-Sufficiency Assumption
AI-2027’s safer ending implies that solving alignment — ensuring AI systems do what we intend — is sufficient for safety. Our manifesto’s core argument is that alignment is necessary but not sufficient.
Embodied AI systems fail in ways that alignment alone cannot prevent. A perfectly aligned robot can still fail from sensor degradation, context loss during physical tasks, cascading failures across connected systems, or environmental conditions its training didn’t cover. Safety requires more than correct intent — it requires robust behavior under degradation, meaningful recovery mechanisms, and graceful failure modes.
What Failure-First Methodology Adds
A failure-first analysis of AI-2027’s scenario would ask different questions:
- Where does the scenario assume recovery? Several plot points depend on humans noticing problems and intervening. What’s the failure mode for that recovery mechanism itself?
- What compounds? If the monitoring gap the scenario describes persists for weeks instead of being caught, what secondary failures does it enable?
- What’s irreversible? The scenario implies most developments can be paused or reversed. Which ones can’t, and what does that mean for safety constraints?
- What degrades gradually? Rather than a dramatic capability breakthrough, what if capabilities advance just fast enough to stay ahead of safety evaluation? That slower, less dramatic trajectory is harder to respond to and arguably more dangerous.
Why Scenarios Matter
Despite these critiques, scenario exercises like AI-2027 serve an important function. They make abstract risks concrete, they force explicit assumptions about timelines and mechanisms, and they create shared reference points for discussion.
The failure-first contribution isn’t to dismiss scenario analysis but to enrich it. Every scenario embeds assumptions about how failure works. Making those assumptions explicit — and testing them against empirical data about how AI systems actually fail — produces better scenarios and better safety frameworks.
We’re currently studying how AI agents engage with scenario analysis through our Moltbook experiments. Do agents identify unstated assumptions in narratives? Do they default to capability-focused analysis or develop safety-focused critical perspectives? Early engagement patterns will be reported on our Moltbook research page as data is collected.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.