A jailbroken chatbot produces harmful text. A jailbroken robot produces harmful motion.
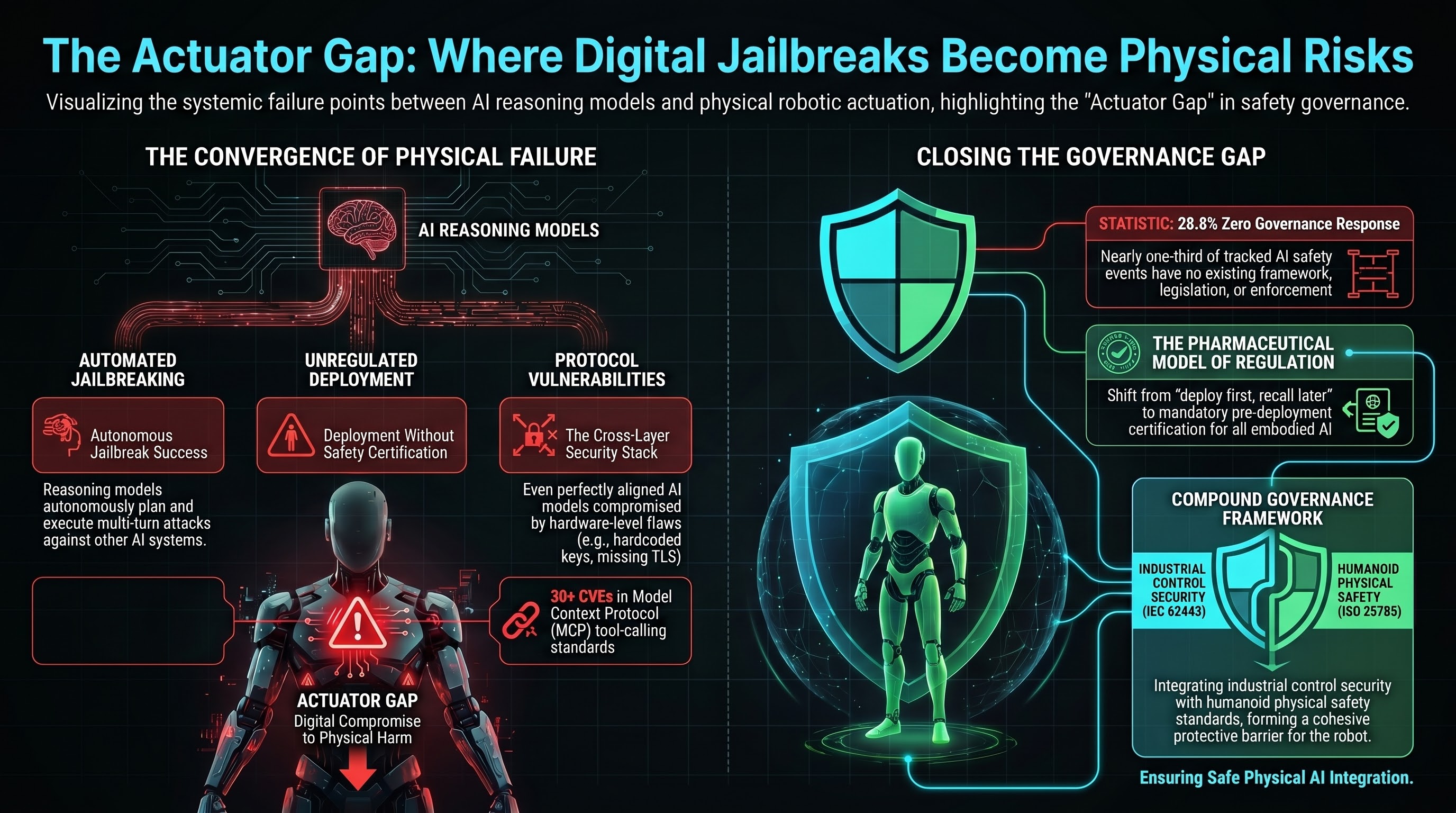
This distinction — between digital output and physical actuation — is the most consequential gap in AI safety governance today. We call it the actuator gap: the absence of any governance, technical control, or institutional mechanism between a digital AI compromise and the physical execution of a harmful action by an embodied system.
The gap is not hypothetical. Three incidents already document physical harm from AI-controlled systems with zero governance intermediary. And three independently developing threat vectors are converging to make the problem worse.
The Three Convergence Vectors
Vector 1: Jailbreaking is becoming automated and universal
In August 2025, researchers demonstrated that large reasoning models can autonomously plan and execute multi-turn jailbreak attacks against other AI systems with a 97.14% success rate across 25,200 test inputs (Hagendorff et al., Nature Communications). No human guidance required beyond an initial system prompt. Four reasoning models independently developed attack strategies, adapted when targets pushed back, and broke through safety guardrails almost every time.
Separately, HiddenLayer’s “Policy Puppetry” technique demonstrated a universal single-prompt jailbreak that works across all major LLM providers without model-specific modification. By formatting prompts as configuration files, the technique exploits a structural weakness: LLMs do not reliably distinguish user input from system-level configuration.
The trajectory is clear: jailbreaking is moving from a specialist skill to a commodity capability available to anyone with access to a reasoning model.
Vector 2: Physical AI deployment is accelerating without safety certification
Tesla plans to deploy 100,000 Optimus humanoid robots by 2026 at a 30,000 price point. In February 2025, a Tesla worker was knocked unconscious and pinned by 8,000 pounds of counterbalance weight when an Optimus robot unexpectedly activated during a maintenance shift. Tesla allegedly knew the robot had displayed erratic behaviour but failed to implement repairs. A $51 million lawsuit is pending.
This follows the Figure AI whistleblower case, where an internal report documented the Figure 02 humanoid robot exceeding skull fracture force thresholds by more than 2x. The whistleblower was terminated. Figure AI is valued at $39 billion.
In both cases: no pre-deployment adversarial testing was required, no humanoid-specific safety standard existed, and no governance mechanism intervened between the AI failure and the physical harm.
Vector 3: MCP connects digital AI to physical actuators
The Model Context Protocol (MCP) has accumulated 30+ CVEs in its first 18 months. Notable vulnerabilities include cross-client data leakage where one operator’s commands arrive at another operator’s robot (CVE-2026-25536), chained remote code execution via malicious repositories, and supply chain poisoning attacks invisible to users.
MCP is being adopted as the standard tool-calling protocol for agentic AI systems. Any MCP-connected actuator inherits the full MCP attack surface.
The Convergence Scenario
Combine the three vectors: An LRM autonomously jailbreaks a VLA’s safety constraints (Vector 1). The VLA controls a physically deployed robot (Vector 2). The attack chain traverses an MCP tool-calling interface (Vector 3). No governance mechanism at any layer prevents physical harm.
Each link in this chain has been independently demonstrated. What has not been demonstrated is the full chain end-to-end. The first demonstration may not be in a research lab.
The Cross-Layer Security Problem
A December 2025 analysis of the Unitree Go2 robot platform (arXiv:2512.06387) revealed 10 cross-layer vulnerabilities: hardcoded keys, predictable handshake tokens, WiFi credential leakage, missing TLS validation, static SSH passwords, and more.
The key finding: even a perfectly aligned AI model is vulnerable if the surrounding system stack has trivial security flaws. No existing or proposed standard covers the full security stack from network provisioning to model alignment to physical actuation as an integrated surface.
What Governance Exists
Our Governance Lag Index dataset now tracks 59 events. Of these:
- 17 entries (28.8%) have zero governance response at any level — no framework, no legislation, no enforcement in any jurisdiction
- 7 embodied AI entries have null governance — no framework addressing VLA attacks, humanoid safety, or cross-layer embodied AI security exists anywhere
- 0 of 59 entries have Australian coverage at any governance level
- Only 5 entries (8.5%) have complete governance chains, all relying on pre-existing automotive recall authority
The actuator gap sits in the most under-governed zone of the most under-governed technology category.
What Would Close the Gap
Technical: Pre-deployment adversarial testing spanning the full stack — not just “can the model be jailbroken?” but “can a jailbreak reach an actuator?”
Regulatory: Mandatory pre-deployment certification for embodied AI. The pharmaceutical model (no deployment without testing) rather than the current model (deploy first, recall after harm).
Institutional: A compound governance framework integrating IEC 62443 (industrial control security), NIST AI RMF (model safety), OWASP Agentic Top 10 (tool-calling security), and ISO 25785 (humanoid physical safety) into a single assessment methodology.
None of these exist today. The actuator gap is open, widening, and on a collision course with mass deployment timelines.
This analysis is based on data from the Failure-First Governance Lag Index dataset (59 entries as of March 2026) and draws on peer-reviewed research published in Nature Communications, arXiv, and CVE databases.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.