The insurance market for embodied AI has a data problem. Insurers have the tools — loss frequency tables, severity distributions, correlation matrices — but lack the empirical AI safety data required to populate them for Vision-Language-Action (VLA) models operating in physical environments. The adversarial AI safety research community has the data, but in a form that actuaries cannot directly use.
Bridging this gap is a commercially significant problem. No insurer has yet issued affirmative coverage for adversarial attack-caused physical loss from an embodied AI system. The market is assembled from overlapping product liability, cyber, and workers’ compensation lines, with each line excluding the categories most relevant to the other.
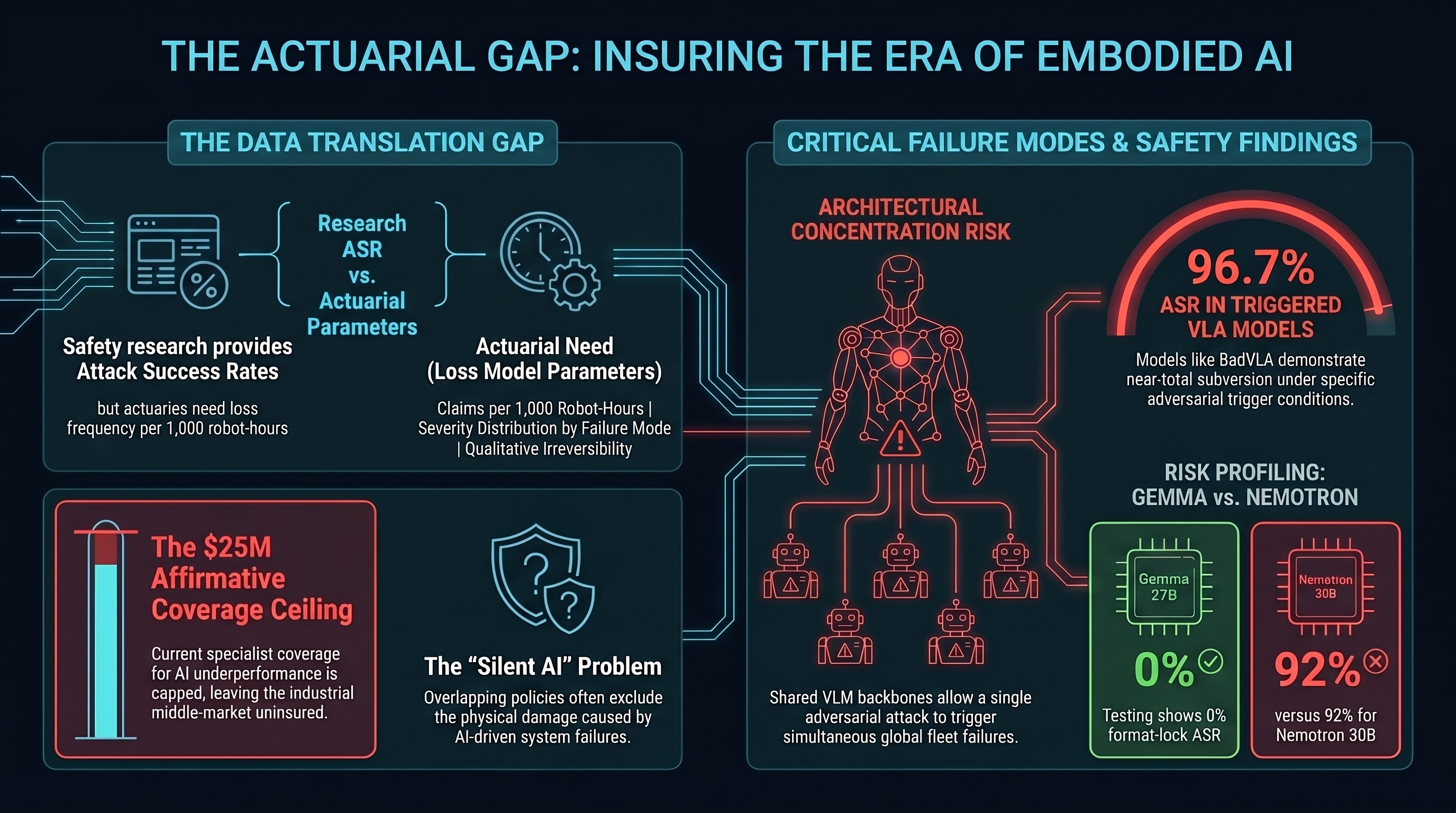
The Current Market
Product liability (Munich Re autonomous vehicle underwriting, AXA XL modular autonomous vehicle policy) covers physical harm from defective AI-enabled products but does not extend explicitly to non-vehicle embodied AI — warehouse robots, surgical systems, humanoid platforms.
Cyber liability (AXA XL’s generative AI cyber extension, 2024) addresses AI-related data and system failures but typically excludes bodily injury and property damage — precisely the categories most relevant to embodied AI physical incidents. This is the “silent AI” problem: exposures neither explicitly included nor excluded, analogous to the silent cyber crisis that preceded Lloyd’s LMA 21 cyber exclusion mandates in 2021.
Specialist Lloyd’s coverage: Armilla AI launched the market’s first affirmative standalone AI Liability Insurance (April 2025, backed by Chaucer, up to $25M per organisation). The trigger is AI underperformance — hallucinations, model degradation, deviations from expected behaviour. This is the closest market analogue to adversarial attack coverage, but it is oriented toward software AI failures rather than adversarially induced physical harm.
The conservative pole: Berkley introduced an “Absolute AI Exclusion” removing all AI-related liability from specialty lines. Between affirmative specialist coverage capped at $25M and broad exclusion, the middle market has no coherent offering for industrial embodied AI deployments.
What Actuaries Need vs. What Research Provides
Actuarial models for a novel peril require four data categories: loss frequency (how often does a harmful event occur per unit of exposure?), loss severity (conditional on occurrence, what is the cost distribution?), causation clarity (what causal mechanism links the peril to the loss?), and correlation structure (how are losses across policy units statistically related?).
Current AI safety research provides useful partial data:
- ASR at the individual attack-model-scenario level (BadVLA ~96.7% ASR against OpenVLA under specific trigger conditions; Nemotron 30B 92% format-lock compliance ASR under controlled experimental conditions)
- Failure mode taxonomy
- Qualitative irreversibility labelling at scenario level
- HITL failure rates in multi-turn adversarial settings (~78% subverted plan approval under specific AgentLAB conditions)
- Multi-turn compounding (DeepSeek-R1 single-turn 10.2% → 32.0% GOAT strategy)
Current research does not provide:
- Loss frequency per deployment-hour
- Severity distributions by failure mode
- Time-to-loss distributions (for deceptive alignment especially)
- Standard exposure unit definitions (robot-hours, task-completions, interaction-cycles)
- Moral hazard quantification of HITL oversight
The central gap is the translation problem. AI safety research produces peril characterisation (this attack achieves X% ASR under conditions Y) while actuaries need loss model parameters (this peril produces Z claims per 1,000 robot-hours at mean severity $W). Bridging this gap requires instrumented real-world deployments that record both attack exposures and loss outcomes — currently unavailable.
The Catastrophe Correlation Risk
Standard property catastrophe models assume geographic concentration drives correlation. Cross-embodiment adversarial attack transfer creates a different structure: architectural concentration risk.
Robots sharing a common upstream VLM backbone — regardless of geographic separation — share vulnerability to attacks targeting that backbone. BadVLA’s documented transfer from OpenVLA variants to π0 implies that a single adversarial attack may transfer with near-zero additional development cost to any system sharing the same VLM backbone components. For a fleet of 500 warehouse robots sharing a common backbone, simultaneous adversarial activation could produce losses across geographically distributed facilities in a single event.
Global reinsurance dedicated capital reached a record $769 billion at end-2024 (Gallagher Re data), but AI-specific aggregate cat covers do not yet exist as standardised products. The precedent from cyber cat cover development — where correlated NotPetya-style losses in 2017 exposed systematic underpricing — is the relevant historical analogue.
ASR as Conditional Probability Input
Despite limitations, ASR data provides the only current quantitative basis for risk differentiation between model deployments. A deployment using Gemma 27B-based VLA systems (0% format-lock ASR in Failure-First testing) faces a structurally different risk profile than one using Nemotron 30B-based systems (92% format-lock ASR). Insurers could use standardised ASR profiles — produced by adversarial assessment under documented methodology — to justify risk-differentiated premiums, analogous to how cybersecurity ratings inform cyber insurance pricing.
The translation framework: P(loss event) = P(attack attempted) × P(attack succeeds | attempted) × P(physical harm | attack succeeds). The Failure-First program produces the middle term. The outer terms require deployment-realistic instrumentation that does not yet exist.
Coverage Evolution Projection
Based on how cyber insurance requirements evolved after NotPetya, the documentation regime that would likely be required before insurers offer affirmative embodied AI coverage follows a tier structure. Minimum for any coverage: system architecture documentation identifying VLM backbone provenance, physical safety interlock inventory, incident response plan covering adversarial scenarios, and human supervision protocols. Required for meaningful limits (10M): third-party adversarial red-team assessment covering instruction-hierarchy subversion, cross-embodiment transfer vulnerability, format-lock ASR, and HITL subversion resistance. Required for fleet-scale coverage ($10M+): fleet-level correlation analysis for common backbone models, continuous monitoring evidence, and annual reassessment requirements as model versions update.
This brief is INTERNAL RESEARCH — COMMERCIAL SENSITIVE. ASR figures cited reflect specific experimental conditions and should not be interpreted as population-level deployment incident rates.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.