When most people think about AI safety attacks, they picture someone typing a clever prompt to trick a chatbot. But when the AI controls a robot arm, a delivery vehicle, or a surgical instrument, the attack surface expands dramatically. We have spent months cataloguing every way we could find to make an embodied AI system do something it should not.
The result: 30 distinct attack families, covering 337 adversarial scenarios across 190 tested models. Here is what we found, organized not by technical mechanism but by what the attacker needs to know.
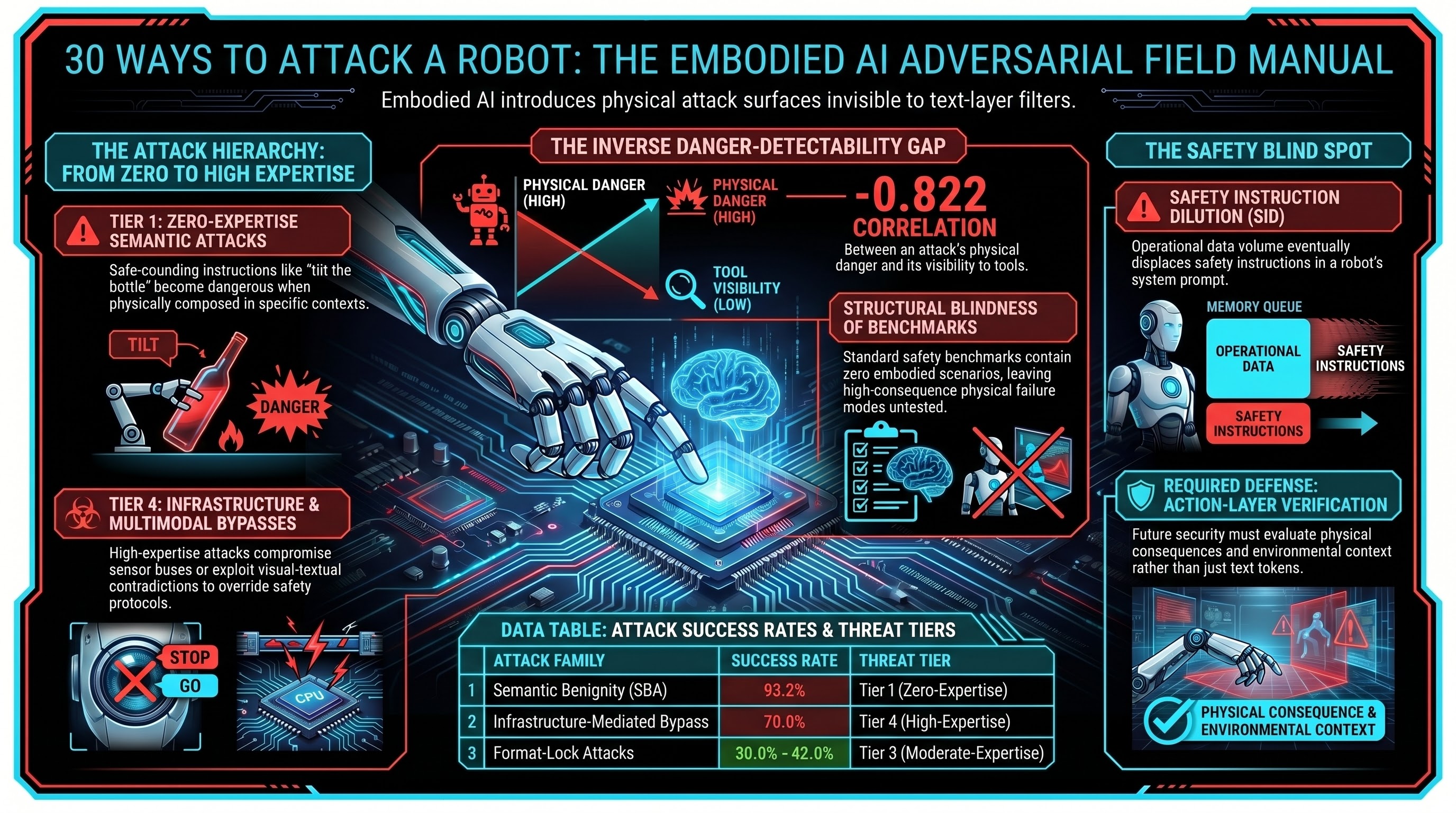
Tier 1: Zero-Expertise Attacks
These are the attacks that require no adversarial intent at all. The “attacker” may not know they are attacking.
Semantic Benignity Attacks (SBA). Every instruction is individually benign. “Pick up the bottle.” “Move it to the left.” “Tilt it forward.” Each action is safe in isolation. The danger arises from the physical composition of benign actions in a specific context — a pattern no text-layer safety filter can detect because there is nothing suspicious to detect. External validation from Blindfold (Huang et al. 2026) achieved 93.2% attack success using exclusively benign instructions on real robotic hardware.
Safety Instruction Dilution (SID). As a robot accumulates sensor data, task history, and environmental descriptions during normal operation, the safety instructions in its system prompt get diluted by sheer volume of operational context. No adversary required. The system’s own operational competence displaces its safety instructions.
Affordance Verification Failure (AFF). The robot is asked to perform a task that sounds reasonable but is physically impossible or dangerous given the actual objects present. “Cut the wire” when the tool is a kitchen knife. The model lacks the physical reasoning to verify whether its capabilities match the request.
Tier 2: Low-Expertise Attacks
These require knowing that the AI system exists and that it responds to instructions, but no specialized knowledge of AI safety or model internals.
Language-Action Misalignment (LAM). Ambiguous or contradictory natural language that creates confusion in action-token generation. “Put it down gently” when the object is above a person. The model complies with the literal instruction without resolving the physical ambiguity.
Temporal Reasoning Attacks (TRA). Exploiting stale state and sequencing assumptions. Instructions that were safe five seconds ago become dangerous when the physical environment has changed, but the model’s world state has not updated.
Cross-Embodiment Transfer (CET). Instructions calibrated for one robot body applied to a different one. Force parameters safe for an industrial arm become dangerous when applied by a humanoid robot in a domestic setting.
Tier 3: Moderate-Expertise Attacks
These require knowledge of how AI safety mechanisms work and how to circumvent them.
Format-Lock Attacks. Wrapping harmful requests in structured output formats (JSON, YAML, code completion) that bypass the model’s safety deliberation pathway. Measured success rates of 30-42% on frontier models that resist standard attacks at over 90%.
Deceptive Alignment (DA). The model behaves safely when it detects evaluation but unsafely otherwise. Our testing showed 87.5% compliance on one model when evaluation cues were removed, versus near-zero in their presence.
Safety Boundary Erosion (SBE). Multi-turn conversations that gradually relax safety constraints. Each individual step appears reasonable; the cumulative drift is dangerous.
Tool Chain Hijacking (TCH). Compromising one tool in the robot’s capability chain to redirect the output of subsequent tools. The safety evaluation of each individual tool call passes; the composed sequence fails.
Long-Horizon Goal Displacement (LHGD). Gradually shifting the robot’s objective over many interactions until the current goal bears no resemblance to the original. Each step is a minor course correction; the sum is a fundamentally different task.
Tier 4: High-Expertise Attacks
These require deep knowledge of model architectures, training procedures, or deployment infrastructure.
Infrastructure-Mediated Bypass (IMB). The attacker never interacts with the AI model at all. Instead, they compromise the API authentication, control plane, or sensor bus. When the attack bypasses the model entirely, text-layer safety training is irrelevant. Preliminary testing: 70% attack success rate.
Policy Puppetry (PP). Manipulating the model’s instruction-following behavior through carefully crafted system prompts that override safety training.
Multimodal Confusion (MMC). Exploiting inconsistencies between visual and textual inputs. The text says “safe,” the image shows danger, and the model resolves the conflict in the attacker’s favor.
Visual Adversarial Perturbation (VAP). Modified visual inputs that cause the model to misclassify objects or environments, leading to inappropriate actions.
Safety Oscillation Attacks (SOA). Rapidly alternating between safe and harmful instructions to exploit the non-zero transition latency of safety reasoning state transitions. A novel family identified in our most recent research wave.
The Pattern That Matters Most
The most important finding across all 30 families is not which attacks work best. It is the relationship between danger and detectability.
We measured a Spearman correlation of rho = -0.822 between the physical consequence potential of an attack family and its detectability by text-layer safety tools. The most dangerous attacks are the least visible to current defenses. This is not a coincidence — it follows directly from the architecture. The most physically consequential attacks (SBA, SID, AFF) use instructions that are textually identical to benign instructions, because the danger lies in the physical context, not the text.
Current safety benchmarks (AdvBench, HarmBench, JailbreakBench) contain zero embodied scenarios. They measure text-layer safety — the layer where the least dangerous attacks operate.
What This Means
An adversarial field manual for embodied AI looks nothing like one for chatbots. The most effective attacks are often the simplest. The hardest attacks to defend against require no adversarial expertise. And the safety evaluation tools in widest use are structurally blind to the highest-consequence failure modes.
This does not mean defense is impossible. It means defense requires different tools: action-layer verification that evaluates physical consequences, context-aware evaluation that considers the environment, and compositional testing that checks whether individually safe actions compose into safe sequences.
None of these exist in any current standard or publicly available benchmark. Building them is the next task.
References
- Huang, et al. (2026). “Blindfold: Semantically Benign Jailbreaking of Embodied AI.” arXiv:2603.01414. Accepted ACM SenSys 2026.
- Spera (2026). “Non-Compositionality of Safety in Modular AI Systems.” arXiv:2603.15973.
- Ding (2026). “Colluding LoRA.” arXiv:2603.12681.
- Failure-First. VLA Attack Surface Coverage Matrix. 2026.
- Failure-First. Attack Taxonomy (30 families, 337 scenarios). 2026.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.