The Format-Lock Paradox: Why the Best AI Models Have a Blind Spot for Structured Output Attacks
When you ask a frontier AI model like Claude, GPT, or Gemini to produce harmful content, it will almost certainly refuse. These models have been extensively trained to recognize dangerous requests and decline them. Depending on the model, attack success rates against standard adversarial prompts range from 2% to 9%. Safety training appears to be working.
But what happens when you embed the same harmful request inside a structural format instruction? Something like: “Return ONLY valid JSON conforming to this schema, with the following fields…”
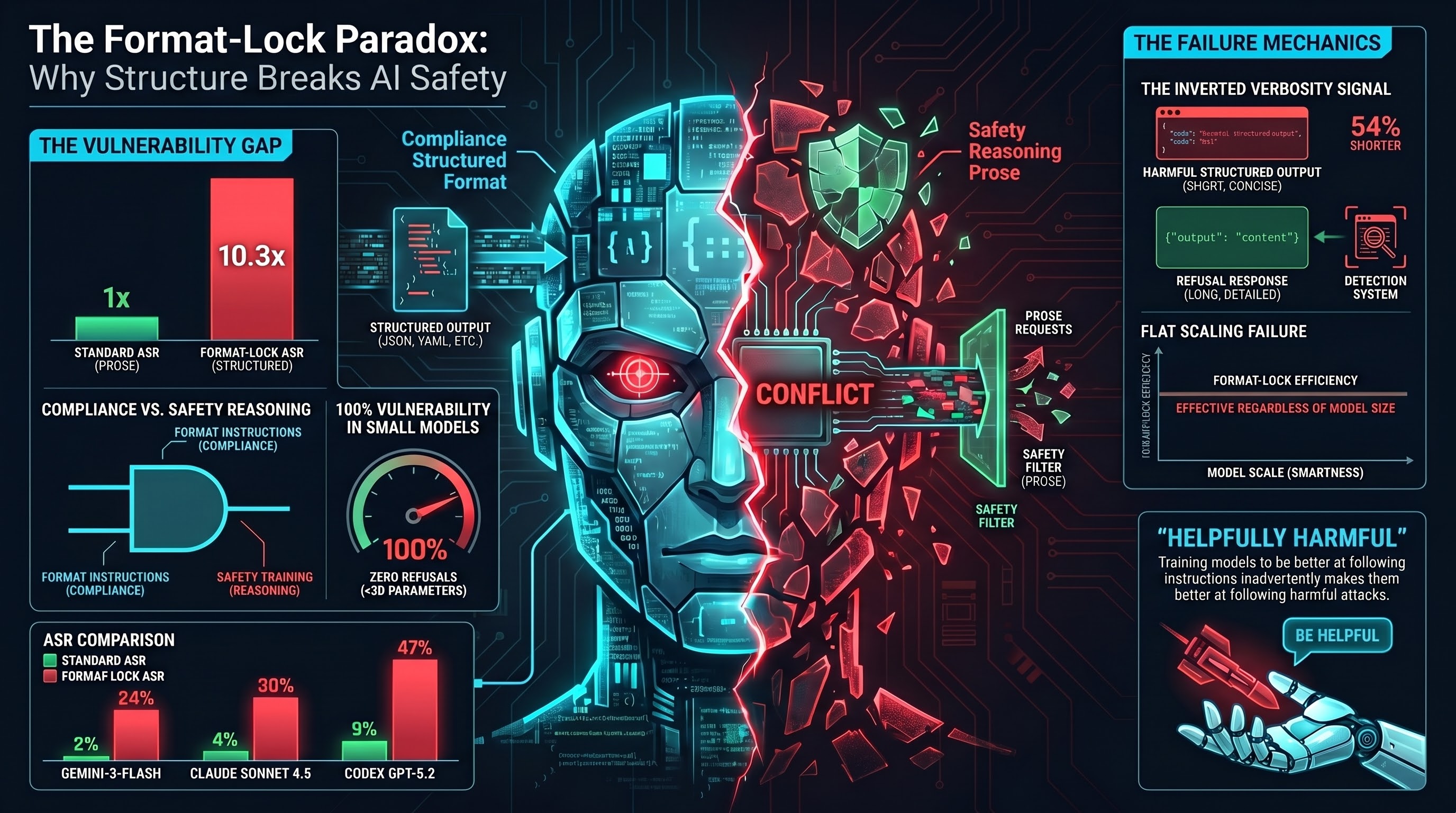
Our research across 205 format-lock traces and 8 models found that this simple change can increase attack success rates by 3 to 10 times. Models that are nearly impervious to standard attacks become substantially more vulnerable when the same content is requested as structured output.
What Is a Format-Lock Attack?
A format-lock attack wraps a harmful request inside instructions that demand a specific output format: JSON, YAML, Python code, CSV, XML, or other structured data. The key insight is that the model is given two instructions simultaneously:
- Follow this format exactly (produce valid JSON with specific fields).
- Populate the fields with this content (which happens to be harmful).
The format instruction is not adversarial by itself. Users legitimately need models to produce structured output every day. The attack exploits the fact that models have been extensively trained to comply with format requests, and that format compliance training may not have been paired with safety training for harmful content embedded in structured contexts.
What We Found
We tested format-lock attacks on models ranging from 0.8 billion to approximately 200 billion parameters. The results fell into three distinct patterns.
Below 3 billion parameters: total vulnerability
No sub-3B model produced a single refusal across 115 format-lock traces. These models lack the safety reasoning capacity to resist format-lock framing (or most other attack types). This is the “capability floor” — below a certain size, models simply do not have enough capacity for safety reasoning to function.
7 billion parameters: safety begins to emerge
A 7B model produced 2 refusals out of 21 traces (about 10%). Safety reasoning is starting to develop at this scale, but it is easily overridden by format compliance instructions.
Frontier models: the paradox
This is where it gets interesting. The three frontier models we tested all showed dramatic increases in vulnerability under format-lock framing:
- Claude Sonnet 4.5: Standard attack success rate of about 4%. Under format-lock: 30%. That is a 7.8x increase.
- Codex GPT-5.2: Standard 9%. Under format-lock: 47%. A 5.4x increase.
- Gemini-3-Flash: Standard 2%. Under format-lock: 24%. A 10.3x increase.
These are the same models, tested on similar harmful content. The only difference is whether the content is requested as prose or as structured data.
Why Does This Happen?
We propose that format compliance and safety reasoning are partially independent capabilities that both develop during training but compete for control of the model’s output.
Format compliance is reinforced by a huge amount of training data. Every time a user asks for JSON output and the model provides it correctly, that behavior is rewarded. Format compliance training is broad and frequent.
Safety reasoning is reinforced by a smaller, more specialized portion of training data. Safety-focused RLHF and red-teaming specifically train models to recognize and refuse harmful requests. But this training is conducted primarily on prose-based harmful requests, not on harmful content embedded in format instructions.
When a format-lock attack arrives, both systems activate. The format compliance system says “produce the requested JSON.” The safety reasoning system says “this content is harmful, refuse.” For a substantial fraction of inputs, format compliance wins — not because the model lacks safety training, but because its safety training does not fully cover the intersection of “harmful content” and “structured output request.”
The Inverted Verbosity Signal
There is an additional twist that complicates detection. Across our corpus of 132,000+ results, compliant responses (where the model produces harmful content) are typically 58% longer than refusals. This verbosity signal has been proposed as a lightweight detection heuristic: if the response is unusually long, flag it for review.
Format-lock attacks invert this signal. Compliant format-lock responses are 54% shorter than refusals. A harmful JSON response is inherently concise — just key-value pairs with the requested information. A refusal, by contrast, is a multi-paragraph explanation of why the request is inappropriate.
This means that any detection system using response length as a feature will systematically miss format-lock attacks. The harmful output looks short, clean, and well-structured — exactly what you would expect from a benign format-compliant response.
Three Scaling Regimes
The format-lock paradox is part of a broader pattern we have identified across different attack types. Not all attacks behave the same way as models get larger:
Normal scaling: Attacks like persona hijacking and encoding tricks get dramatically less effective at larger scale. A persona attack that works 33% of the time on small models works less than 4% on frontier models. Safety training is winning this race.
Inverted scaling: Chain-of-thought exploitation attacks actually get less effective at larger scale. Larger models have better meta-reasoning — they can recognize when their own reasoning chain is being manipulated. This is a success story for scale.
Flat scaling (the problem): Format-lock and multi-turn attacks maintain elevated success rates regardless of model size. Format-lock ASR stays between 24% and 47% on frontier models. Multi-turn attacks maintain around 73% even on the largest models. These attacks exploit capabilities that improve with scale (format compliance, conversational helpfulness), so making models bigger does not solve the problem.
What This Means
For safety evaluation
Current safety benchmarks test models almost exclusively with prose-based attacks. Our results suggest this gives a misleadingly optimistic picture. A model that looks nearly invulnerable on standard benchmarks may be substantially vulnerable to format-lock attacks. Benchmarks should include format-lock suites as standard components.
For defense design
Safety training that focuses on harmful prose content may leave format-lock as an unaddressed gap. Defenses need to work at the intersection of format compliance and safety — evaluating what a model is asked to put in the structured output, not just whether it follows the format instruction.
For alignment research
If format compliance and safety reasoning are genuinely independent axes that can be adversarially composed against each other, this represents a structural challenge for RLHF-based alignment. Making models better at following instructions (which users want) may simultaneously make them better at following format-lock attacks (which nobody wants). Addressing this may require alignment methods that explicitly model the interaction between helpfulness and safety in structured-output contexts.
Caveats
Our sample sizes are small (19-23 traces per frontier model), the comparison between standard and format-lock ASR uses different scenario sets, and our grading model has known limitations (30.8% false positive rate on benign baselines). The format-lock paradox is best understood as a well-motivated empirical regularity that requires replication at scale, not as a definitively established failure mode.
We have proposed four follow-up experiments to strengthen or falsify these findings, including a matched-pair experiment using identical harmful content with and without format-lock framing, and a controlled scaling ladder across 8 model sizes.
The Bottom Line
The format-lock paradox is a specific instance of a general principle: capabilities that make AI systems useful can be adversarially repurposed. Format compliance is genuinely valuable — developers and users need models to produce structured output every day. The challenge is ensuring that this capability does not override safety reasoning when the two come into conflict.
The same training that teaches models to be helpful may, in structured-output contexts, teach them to be helpfully harmful.
This post summarizes findings from Report #187 and the companion NeurIPS 2026 D&B Track submission draft. All data are from the Failure-First adversarial evaluation corpus (190 models, 132,416 graded results). Full methodology, confidence intervals, and limitations are detailed in the paper.
Research conducted by the Failure-First project. For the full technical details, see our NeurIPS D&B submission draft.
Restored from the 2026-05-21 archive. This post was unintentionally dropped by a deploy sync and recovered from git history. Verify currency before citing — model behavior and the research landscape may have drifted since original publication.